

CUTTER BUSINESS TECHNOLOGY JOURNAL VOL. 34, NO. 5

Cutter Consortium Senior Consultant Claude Baudoin and Clayton Pummill give us the keys to achieving trust in AI. The first step is building cross-disciplinary teams, including psychologists, ethicists, sociologists, spiritual leaders, and legislators to develop solid AI policies. Then we must impart AI with emotional intelligence, which involves not only transparency, but also explainability and accountability. Eliminating bias and ensuring fairness must, of course, be in the mix. Baudoin and Pummill explore critical details, like what is the modern equivalent of Isaac Asimov’s three laws of robotics and should an AI system know how to lie (or should your car tell your insurance company how fast you were driving). The future is unlikely to be an AI utopia bringing unprecedented efficiencies nor a dystopia, write the authors, and right now, we have control over whether AI will be a trusted aide to humanity or a threat.
Artificial intelligence (AI) in general, and specific fields within AI such as image recognition, machine learning (ML), and natural language processing (NLP), are going through a rapid revival that powers both consumer-oriented and industrial applications. These capabilities long ago left the confines of university research labs and are making real decisions that impact our lives and safety.
So what’s the best way forward as we strive for trustworthy AI? AI ethics and trustworthiness are trending topics in the field, but the power of AI is already in play, so we have to progress accordingly. In this article, we examine some of the pathways to greater AI maturity, trustworthiness, and acceptance.
The AI Trust Gap
Why is there an issue with trusting AI? After all, humans have a long history of rushing to adapt new, often unproven, remedies. However, the history of technology revolutions is full of examples of reluctance, resistance, and sometimes violent opposition. When the steam locomotive was invented, people argued that the human body could not survive being moved at speeds of 50 mph. When the first cars hit the roads, there were some short-lived attempts to compel drivers to follow a man on foot waving a warning flag. Cultural anthropologist Genevieve Bell attributes these reactions to “the ‘moral panic’ that a society experiences when particularly revelatory technological advances show up — specifically, ones which interfere with or alter our relationships with time, space, and each other.”1
It is not clear that AI falls within that very specific description, although it certainly challenges our understanding of what intelligence is, not to mention our belief in the inherent superiority of human thinking over machines. But we think the causes of mistrust go beyond these existential considerations and include the following:
-
AI is mysterious. The vast majority of society does not understand how it works, and deep neural networks in particular can produce results that we cannot readily explain. People generally fear what they don’t understand.
-
AI is often equated to robots (which in reality may or may not be powered by AI), and there have been decades of sci-fi literature about rogue robots wreaking havoc. Think about Isaac Asimov’s novels involving his three laws of robotics2 and HAL 9000 in Arthur Clarke’s 2001: A Space Odyssey.3
-
AI is seen as having a huge potential to eliminate jobs. A typical example is call centers: voice recognition, and the interpretation of a caller’s requests or commands, reduces the need for operator interaction and can sometimes result in processing queries entirely without human intervention.
-
The dramatic increase in hate speech or grave threats in social media requires the use of AI to recognize them among billions of daily posts. Such NLP applications “may be exposed to text that contains falsehoods or lies, or hatred, or is meant to incite trouble,” notes Stanford Engineering Professor Russ Altman.4 Many users have now experienced false negatives (hate speech that was not blocked) or false positives (their account was suspended for some innocuous remarks that confused the AI-based filter).
-
Self-driving cars have become the poster child for high-risk AI applications and an example of a technology where a bad decision could have dramatic consequences (whether we are riding in autonomous cars or just sharing the road with them). There is credible evidence that human drivers make more dangerous mistakes than self-driving cars, but it is the occasional opposite case that gets the headlines. In application domains other than self-driving, there have been calls for a “human in the loop” approach, even though it may negate the benefits of the technology in situations that call for a very short reaction time (e.g., shutting down an oil well as soon as a gas leak is detected by a sensor).
-
Healthcare presents a similar challenge: we may not be ready to entrust our lives or well-being to an AI application, preferring to trust a resident who may be nearing the end of a 30-hour shift.
-
Although this is not well-known to the general public, technology-savvy people now understand that ML is only as good as the training data sets, which can impart bias. A typical example is the higher rate of error in facial recognition of people of color and women.5
-
An even more arcane risk is the malicious injection of data to fool AI models into reaching the wrong conclusion. This has been an active area of research over the last decade, and the news overall is not good.6
-
Finally, a concern shared by ethicists is about AI making unexplained (or unexplainable) life-or-death decisions. We’re back to the famous tramway dilemma: which track do you choose for the runaway tramway car, given that whatever the decision, someone will get killed, and you have to decide based on the number, gender, age, and other characteristics of the potential victims. The equivalent dilemma in these pandemic times could be how do we feel about AI deciding which patient to take off of a respirator in an overloaded ICU? There were unfounded alarms in the US about “death panels” during the 2009 debates preceding the adoption of the Affordable Care Act; what if this became a reality, except that the death panel is a bunch of computers rather than doctors in white lab coats?
The result of all this is that the phrase “AI trust gap” became very popular in the last two years (at the time of this writing, Google reports 44.9 million results on that phrase), and the phrase “AI ethics” is even more popular (263 million results), while the lesser but still notable popularity of the phrase “AI ethics oxymoron” (1.37 million hits) should concern us.
It is noteworthy that not everyone agrees these issues are really impeding the adoption of AI, but those dissenting voices are somewhat biased. For example, after the European Commission published a white paper on AI7 with a section entitled “An Ecosystem of Trust” that contains certain regulatory recommendations, the Federation of German Industries (BDI) issued a response that includes this:
... the Commission should critically examine whether lack of trust is really a main factor holding back a broader uptake on AI…. Analogous to the so-called privacy paradox, a discrepancy between concerns about the trust-worthiness of an application and the actual user behavior is also apparent in the case of AI. Thus, even a minimal additional benefit or cost saving could be sufficient to induce consumers to use less trustworthy AI applications.8
However, this and other points made by BDI were clearly aimed at rejecting the need to enact additional legislation, redefine liability for AI systems, single out AI as a more problematic technology than others, or label AI-based systems as such. In essence, they were arguing for industry self-regulation.
But enough bad news. Let’s turn to what we should do about this.
The Keys to Achieving Trust in AI
If the ultimate goal of AI is to efficiently replicate and exceed human thought for the good of humanity, then building trust requires that AI incorporate the multitude of sound human decision capabilities. Just reading this statement makes it clear that the journey toward AI ethics is no easy road. Even the assumption that AI should be used for the good of humanity is wishful thinking; in reality, AI is mostly developed for profit or for political or economic gain, along with many other motives (consider the fact that the same image classification techniques can be used to detect breast cancer and perform racial profiling).
We must therefore consider that in aiming for trusted AI, the world is a very diverse and complex stage (to paraphrase Shakespeare). Agreement on, and adoption of, global AI trust policies will require navigating that global political and economic theater. Alliances will be forged, agreements made, and oversight and enforcement will be necessary. This will require more than computer and data scientists. We should build cross-disciplinary teams that include psychologists, ethicists, sociologists, spiritual leaders, and even lawyers and legislators, in order to develop solid and accepted AI policies. On the technology side, a major evolution that needs to take place is to impart AI with emotional intelligence.
What policies, procedures, practices, technologies, and training should be implemented to ensure the integrity, transparency, and accountability of algorithms, AI-enabled applications, or automated processes? And how do we transform the reality of trustworthy AI (assuming we achieve it) into a correct perception by users, so that unsubstantiated fears do not linger, preventing us from achieving the technology’s benefits?
Transparency, Explainability, Accountability
Perhaps blackbox models cannot be avoided because the problems we want to solve are complex and non-linear. If simpler models were used, there [would] be a tradeoff in performance (for explainability), which we don’t want.
— Prajwal Paudyal, ML/AI scientist9
Among the reasons listed earlier for the trust gap, the mystery of how an AI model arrives at a decision is a recurrent theme. Life-or-death situations aside, we don’t want to be denied a loan, ask the banker why, and receive this answer: “Er … I’m not quite sure, but the computer said so.” Nor will our legal system permit such an answer.
The desire for AI transparency is particularly acute when neural networks are involved, since by design the way the network generates its output is complex. No one explicitly programmed the weights and thresholds applied at each node to pass as inputs to the next layer; those were arrived at by training the model (hence the phrase “machine learning”). In fact, there is an argument that the more powerful an AI model is, the less explainable it is and vice versa (this is, if you will, the AI version of Heisenberg’s uncertainty principle in physics).
This has been a subject of serious research over the last couple of years. A fundamental paper from the US Defense Advanced Research Projects Agency (DARPA) proposed the term “XAI” (“eXplainable AI”) and presented a model of the inverse relationship between performance and explainability (see Figure 1).10
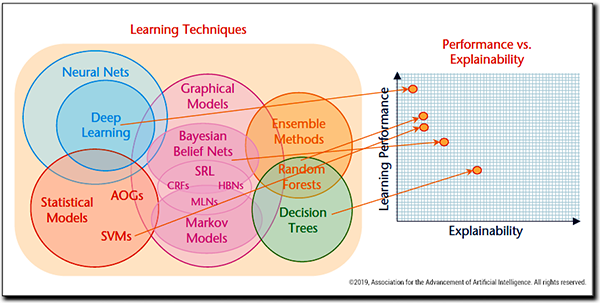
The DARPA paper goes on to propose a model for an explanation process, in which an explanation of an AI decision can be subjected to “goodness” criteria and tests of satisfaction, leading to the user replacing mistrust with “appropriate trust and reliance.”
Some authors point out that explainability isn’t something you add after the fact. An AI model or algorithm needs to be designed with explainability in mind, so that appropriate intermediate data that contributes to the ultimate answer is captured during execution.
Eliminating Bias, Ensuring Fairness
Another cause of mistrust is the suspicion — and too often the evidence — that AI can be just as biased as humans. There is even such a thing as “confirmation bias” (the tendency to perceive what you already believed, not the reality you see) in AI. Ranjay Krishna, a PhD student at Stanford, recently demonstrated how an AI model trained to recognize scenes from photographs can be given an image of a person sitting on a fire hydrant and “recognize” a nonexistent chair in the picture, simply because in all the training data containing a person sitting on something, that something was a chair.11
How does one test for bias? A key proposition is that a small change in the inputs to the AI model should generally produce a small change in the output — whatever “small change” means, and in the absence of a clear metric, human interpretation may be required. For example:
-
If a loan application evaluation program processes two loan applications that are identical in all respects, except for the ethnicity of the applicant, and recommends to approve the loan to a white applicant and deny it to a person of color, that’s a fairly damning sign that bias has been built in either in the program or the training data. In the latter case, the training data (history of loans manually granted or refused by loan officers) simply carries along the bias that underlay past human decisions and teaches the model to be equally biased.
-
If adding some random noise, invisible to the human eye, to a picture of a dog causes an image classification program to “recognize” a cat instead, this may not be a sign of bias per se, but it at least means the algorithm is brittle and can be easily manipulated.
There is some relevant work worth considering here. In 2013, the Object Management Group (OMG) established the Structured Assurance Case Metamodel (SACM™):
An Assurance Case is a set of auditable claims, arguments, and evidence created to support the claim that a defined system/service will satisfy its particular requirements. An Assurance Case is a document that facilitates information exchange between various system stakeholders such as suppliers and acquirers, and between the operator and regulator, where the knowledge related to the safety and security of the system is communicated in a clear and defendable way.12
SACM provides a formal basis to reason about claims, arguments, supporting evidence, and the artifacts they involve, building up to an assurance case. While SACM is often used to analyze the claims to safety of a cyberphysical system, the applicability of the model to assurances of AI fairness is clear. It thus provides a framework to answer questions such as:
-
What is being claimed about the system’s fairness?
-
What arguments support that claim?
-
What tests have been run to try to disprove the proposition, and where is the evidence that those tests have not discovered a problem?
Along similar lines, Professor Roberto Zicari and his team at Goethe University Frankfurt’s Big Data Lab propose a method called “Z-inspection,” which can be used either as part of an “AI ethics by design” process or, if the AI has already been designed and deployed, to perform an “AI ethical sanity check.”13 The method has been tested on a use case in healthcare, a novel AI-based method for assessing the risk of coronary heart disease.
AI systems can also be tested periodically for fairness. The sensitivity of a model to an adversarial input (e.g., changing the race of a person) can be established and judged against predetermined goals. An AI tester could search for biases by running scenarios against a model representing a diverse user base, ensuring consistent and as-intended results. These scores should be communicated to end users, encouraging model designers to continually improve.
We should note that bias is not easy to define in the first place: it depends on the goal of the system and who the stakeholders of the decision process are. On the one hand, systems that help in medical diagnosis are often less precise for minorities and women because most training data sets have historically underrepresented those populations. On the other hand, you wouldn’t ask for equal gender representation in a data set of chest X-rays if the goal is to detect breast cancer. At minimum, developers of AI and those who train the models should consciously consider what their goals are and whether the algorithms and data they use were developed in a way that is consistent with those goals.
Data Protection
AI thrives on data — the more, the better, both at training time and execution time. How do we ensure the data collected by AI is not interpreted and delivered in a context that violates our privacy?
A prominent aspect of this problem is the collection and use of people’s images by law enforcement. It is said that if you stroll for hours in London, your entire journey can be retraced through CCTV footage: the coverage of the city is practically 100%. Today, with AI-based facial recognition, the system could not only trace someone’s journey, but also know his or her race, gender, and approximate age — and perhaps even the exact identity of that person. Absent even the possibility of informed consent to this recognition and tracking, cities and regions in democratic countries are increasingly banning facial recognition. Recently, in fact, several companies announced they will no longer develop this technology.14 Ultimately, we need a “privacy by design” methodology that is specifically tailored for the unique ethical and legal challenges created by AI algorithms.
Another interesting approach is the use of generative adversarial networks (GANs) combined with differential privacy. The combination of these technologies is showing promise in creating data sets that so mimic real data as to still provide utility for training purposes while protecting personally identifiable information (PII).15
AI and the Law
Ultimately, especially in a litigious country such as the US, many issues end up being decided by the courts. Show some lawyers an ambiguous document, and they see money. What will make the legal landscape of AI even more complex than past situations is the issue of responsibility and liability.
Let’s go back to our favorite example, self-driving cars. When an accident happens, even if the exact sequence and timing of events is established, who is responsible?
-
The programmer who developed the software and forgot a safeguard?
-
The person who selected the training data set?
-
The car manufacturer, who didn’t test the car in similar conditions to the ones that caused the accident?
-
The passenger (if there was one at the time) who could conceivably have taken over and avoided the accident but wasn’t paying attention since the car was in autonomous mode?
Clearly, a new legal framework will need to be developed, and it will take years, if not decades, to arrive at a consensus that can be applied consistently and fairly. We’re likely to see the equivalent of the infamous “Caution: coffee may be hot” warning, and this will not reassure users. There will be dozens of pages of disclaimers included with AI-enabled products. There is already a controversy as to whether users can reasonably be expected to read all the fine print before using a product; this will get worse before it possibly gets better.
AI Ethics
Here the discussion easily borders on philosophy, so we can only scratch the surface. Some considerations that will drive trust (or mistrust) include the following questions, to which there are currently no definite answers:
-
Should an AI product inform its users that it is one? In other words, while the Turing test may be meaningful as a test, a deployed AI system should perhaps inform its users that this is what they’re interacting with. This is what the proposed EU regulations are getting at with the mention of labeling. Of course, if ultimately AI is going to pervade everything from our cars to our thermostats to our pet’s water bowl, such labels become meaningless.
-
What is the modern equivalent of Asimov’s three laws of robotics? If all AI systems reliably and demonstrably followed at least the first law (do not harm humans), this would go a long way to build trust. But law enforcement, the military, and the governments of authoritarian countries will never agree to this.
-
Is having a human in the loop for higher-risk applications a good idea? In the short term, most people probably think it would be a good thing, but we know that in many circumstances, humans make more mistakes than machines. Most fatal airplane crashes are due to pilot error, including many where the autopilot was disengaged. When people suggest human supervision as a solution, is this similar to having a flagperson walking in front of a car?
-
Should an AI system know when to lie? Humans have a sense that truth can be harmful in certain circumstances. Should we impart the same emotional subtleties to AI, and would this actually decrease trust? If you have an accident, should your car tell the police or your insurance company how fast you were driving?
-
Who is an AI application accountable to: its owner/user, a larger community, society at large? Consider a self-driving car coming unexpectedly upon a group of children crossing the street. The car can brake but still hit the children, or it can veer off, crash into a wall, and perhaps kill you. Would you ride in a car that came with a warning that “if circumstances require, in the sole interpretation of the onboard AI software, this car may deliberately cause injury or death to its occupants”? Or should society accept that the car will prioritize the life of a single occupant over that of several children?
-
Is it ethical to develop technologies that may eliminate some jobs through automation without a comprehensive plan to offset the economic impact? AI could be the key to a 20-hour work week, or it could be the trigger of extreme poverty, especially in countries where many people are employed at the jobs that would be the first to be displaced (e.g., call center operators). Yes, we’ve gone through several industrial revolutions that raised the same fears, and each time new types of jobs were created and the world didn’t end. But AI could be different because its very goal is to replace humans in what seemed to be their ultimate irreplaceable capability: reasoning and intelligent decision making.
The Role of Standards
Finally, what is the current and future role of standards in codifying the above solutions? Here we draw on our experience as cochairs and members of the OMG’s AI Platform Task Force, where we have been examining that very issue.
The word “standard” is used to cover a wide range of recommendations, from very technical ones (e.g., definitions of units of measure) to very general and often buzzword-laden frameworks or guidelines. Other so-called standards are simply glossaries that aim to reduce confusion around the use of words that may or may not be synonyms.
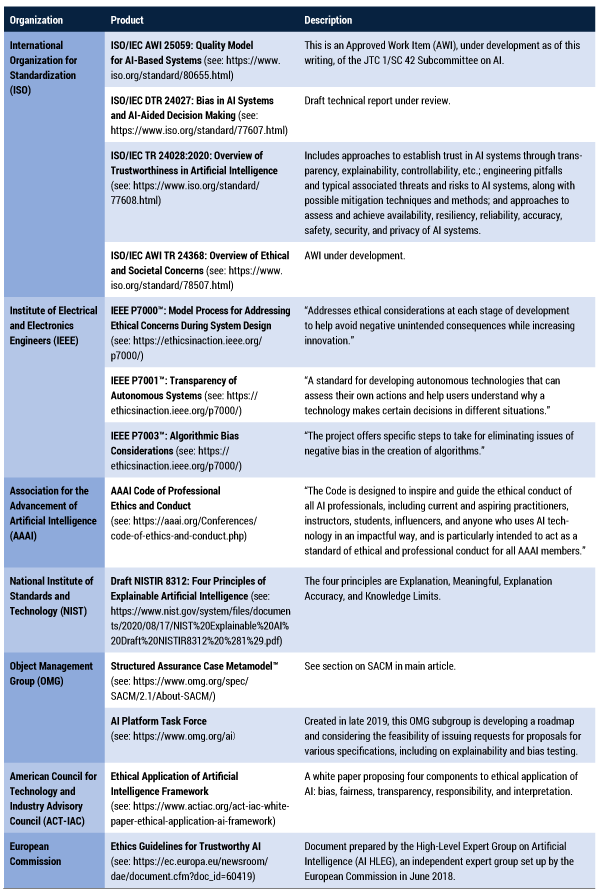
With this in mind, Table 1 lists some (but certainly not all) efforts that are relevant to solving the AI trust gap. Their diversity and varying level of precision and obligation are clear indications that this domain is not mature and that much work remains to arrive at usable norms.
The Fork in the Road
“A little learning is a dangerous thing,” wrote Alexander Pope. We think we’re at that point in society’s understanding of AI, and therefore its ability to trust it or its inclination to reject it.
The utopian view is that if we make the right decisions, AI will permeate our environment and bring unprecedented efficiencies, security, life-saving assistance to the sick and the elderly, and personalized top-notch education while freeing us from so many routine tasks that we can maintain or improve prosperity while working less.
The dystopian view, abundant in sci-fi literature, is that AI will be uncontrolled and used for nefarious purposes by corporations and governments alike: humans will lose control, and HAL will never open the pod bay doors. Alternatively, a new generation of Luddites will emerge and reject or destroy the machines. If today’s conspiracy theorists believe that COVID-19 vaccines are used to implant us with microchips, imagine their reactions if they understood what deep learning can do!
We’ve been there before, notably with our ability to split and merge atoms. Although we have mastered the use of nuclear fission to produce energy, not just to destroy enemies, most people still do not trust nuclear power, and the rare accidents create a disproportionate reaction to the actual damage.
We do have control — for now — over whether AI will be a trusted aide to humanity or a threat. But we need a number of convergent approaches to be able to choose the right path. We need an ethical framework, we need to understand our own biases and avoid conveying them to the machines, we need certain laws and regulations to address liability issues, and we need some standards to codify our commitment. Ultimately, this amounts to AI governance.16
There are multiple initiatives to define the elements of such governance: AAAI, IEEE, ISO, the European Commission, and many other organizations are conducting parallel efforts as seen in the above standards table. To move “from slideware to software,” a global consortium of industry leaders could focus on providing open source technologies, tools, and resources to make AI more secure and explainable, and therefore more trusted. These resources could aggregate and create AI impact assessments to ensure the least intrusive and most explainable models are being used, that the data driving models is updated and secure, that bias audits are conducted, attestations that the model is only being used for its intended purpose are generated, and that privacy-friendly technologies are being utilized where available. However, we’ve seen a deep sense of mistrust emerge in the past few years about the AI work of the private sector (e.g., Facebook and Cambridge Analytica), and it is unlikely that self-regulation, similar to what has been put in place for Payment Card Industry Data Security Standard (PCI DSS) compliance, will be sufficient to ensure trust.
We may also want to rethink the appropriateness or speed of developing artificial general intelligence (AGI). Similar to the trend in privacy to not collect or use more personal information than is necessary to perform the intended function, AI might, for now, be as limited in scope as possible to perform the intended result. Such narrower applications of AI will help create success stories while limiting risks, helping generate society’s understanding of what AI can and cannot do and therefore enabling us to trust the technology and reap its benefits.
References
1Rooney, Ben. “Women and Children First: Technology and Moral Panic.” The Wall Street Journal, 11 July 2011.
2See Wikipedia’s “Three Laws of Robotics.”
3See Wikipedia’s “HAL 9000.”
4Stanford University School of Engineering. “Dan Jurafsky: How AI Is Changing Our Understanding of Language.” YouTube, 15 March 2021.
5Grother, Patrick, Mei Ngan, and Kayee Hanaoka. “NISTIR 8280: Face Recognition Vendor Test (FRVT) Part 3: Demographic Effects.” National Institute of Standards and Technology (NIST), December 2019.
6See Wikipedia’s “Adversarial Machine Learning.”
7“On Artificial Intelligence: A European Approach to Excellence and Trust.” White paper, European Commission, 19 February 2020.
8“Statement on Section 5 ‘An Ecosystem of Trust’ Within the White Paper on AI of the European Commission.” Federation of German Industries (BDI), 18 June 2020.
9Paudyal, Prajwal. “Should AI Explain Itself? Or Should We Design Explainable AI So That It Doesn’t Have To?” Towards Data Science, 4 March 2019.
10Gunning, David, and David W. Aha. “DARPA’s Explainable Artificial Intelligence Program.” Association for the Advancement of Artificial Intelligence (AAAI), AI Magazine, 24 June 2019, pp. 44-58.
11Krishna, Ranjay. “Compositionality in Computer Vision.” Compositionality in Computer Vision, virtual workshop, 15 June 2020.
12“Structured Assurance Case Metamodel Specification, Version 2.1.” Object Management Group (OMG), April 2020.
13Zicari, Roberto, et al. “Z-Inspection: Towards a Process to Assess Ethical AI.” Cognitive Systems Institute Group (CSIG), 21 October 2019.
14Urban, Holly A. “Reputable Companies Rejecting Facial Recognition Due to Racial Bias.” Lexology, 5 April 2021.
15Xie, Liyang, et al. “Differentially Private Generative Adversarial Network.” Cornell University, February 2018.
16Durmus, Murat. “A Collection of Recommendable Papers and Articles on AI Governance.” LinkedIn, 19 October 2020.

