

Starting in 2023, a number of fast-food chains deployed AI in an attempt to reduce mistakes and speed up service. Since then, many comical videos of customer interactions with AI at drive-throughs have gone viral. In one widely shared clip, a customer orders 18,000 water cups to “shut down” the system so he can speak to a human. In another, a frustrated driver grows increasingly angry as AI repeatedly asks him to add more drinks to his order. After millions of views, Taco Bell found itself rethinking its AI rollout in the face of ridicule.
It’s hilarious — but also instructive. The AI didn’t fail because it lacked linguistic skill. If anything, it was too good at turning speech into an order. The failure was that no one connected the AI’s impressive fluency to the everyday constraints of the restaurant: no one orders 18,000 drinks at a drive-through.
This scenario captures the paradox of AI in 2025. Models like ChatGPT-5, Claude 4 Opus, and Gemini 2.5 are astonishingly capable (nearly indistinguishable on many benchmark tests). But in practice, they make mistakes humans would never make. The problem isn’t performance. It’s proximity and explainability — how well models align with the messy, human, real-world environments they’re dropped into.
The Plateau No One Wants to Admit
For years, AI progress felt unstoppable. GPT-3 blew people away with its fluency. GPT-4 showed surprising reasoning. Today, ChatGPT-5, Claude 4 Opus, and Gemini 2.5 systems are capable of sophisticated reasoning, multilingual fluency, and even multimodal interaction. But take a step back, and you’ll notice the differences between them are slim (see Figure 1).
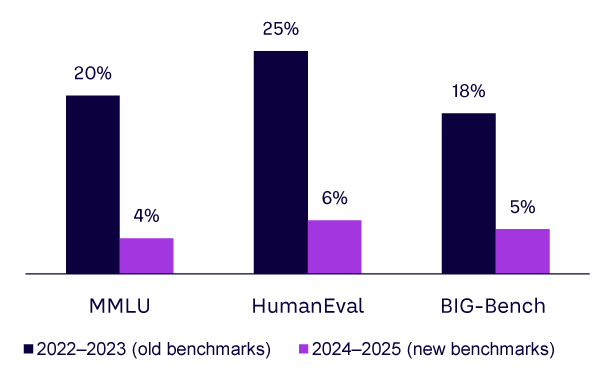
On MMLU (measuring Massive Multitask Language Understanding, a benchmark that tests AI models’ ability to answer multiple choice questions across 57 academic/professional subjects), as of September 2025, the leading models hover around 90% in terms of accuracy. On HumanEval, which tests coding, they differ by only a handful of points. Even open source challengers like DeepSeek function at similar levels.
The Stanford “AI Index Report 2025” notes that frontier models are converging on most static benchmarks and that incremental improvements are disproportionately costly while yielding marginal real-world value.
Meanwhile, the leaderboards that once guided the industry are under fire. In early 2025, a tuned, nonpublic variant of Meta’s Llama 4 Maverick was submitted to the popular Chatbot Arena, where models are ranked via human head-to-head voting. It scored far higher than the released model, sparking accusations of benchmark gaming and forcing Arena’s operators to tighten policies. Researchers have warned of the “leaderboard illusion” (also known as Goodhart’s Law): once a measure becomes the target, it stops being a good measure. Benchmarks were once a proxy for progress. Now they’re often little more than marketing theater.
Why the Taco Bell Story Matters
The 18,000 water cup fiasco makes for easy laughs. But it demonstrates something important: AI often fails not on capability, but on context.
Look at what went wrong:
-
Norms failure. The system didn’t realize that the ask was unlikely to be the result of a genuine need.
-
Data check failure. AI didn’t know that 18,000 was absurd given the store’s inventory.
-
Workflow failure. The order was accepted by the POS system without guardrails.
-
Governance failure. No escalation was triggered before the blunder reached a paying customer.
And although funny in a fast-food setting, the same pattern can be devastating elsewhere. For example, in 2024, Air Canada’s chatbot misinformed a customer about how to access a bereavement discount. A Canadian tribunal sided with the passenger, rejecting the argument that the chatbot was a “separate entity.”
It’s certainly easy to imagine many such missteps in implementation. If an HR recruitment bot, for example, isn’t integrated with the corporate calendar system, it could easily schedule overlapping interviews, leaving recruiters scrambling, candidates frustrated, and the company’s brand at risk.1
These aren’t failures of intelligence. They’re failures of proximity — when AI isn’t properly tethered to the data, processes, or rules of the organizations deploying it.
Note
1For an example of an AI sales agent struggling with scheduling, see Joe Allen’s Amplify article: “Why Judgment, Not Accuracy, Will Decide the Future of Agentic AI.”
[For more from the authors on this topic, see: “Taco Bell, 18,000 Waters & Why Benchmarks Don’t Matter.”]


