

AMPLIFY VOL. 38, NO. 6

Starting in 2023, a number of fast-food chains deployed AI in an attempt to reduce mistakes and speed up service. Since then, many comical videos of customer interactions with AI at drive-throughs have gone viral. In one widely shared clip, a customer orders 18,000 water cups to “shut down” the system so he can speak to a human. In another, a frustrated driver grows increasingly angry as AI repeatedly asks him to add more drinks to his order. After millions of views, Taco Bell found itself rethinking its AI rollout in the face of ridicule.1
It’s hilarious — but also instructive. The AI didn’t fail because it lacked linguistic skill. If anything, it was too good at turning speech into an order. The failure was that no one connected the AI’s impressive fluency to the everyday constraints of the restaurant: no one orders 18,000 drinks at a drive-through.
This scenario captures the paradox of AI in 2025. Models like ChatGPT-5, Claude 4 Opus, and Gemini 2.5 are astonishingly capable (nearly indistinguishable on many benchmark tests). But in practice, they make mistakes humans would never make. The problem isn’t performance. It’s proximity and explainability — how well models align with the messy, human, real-world environments they’re dropped into.
The Plateau No One Wants to Admit
For years, AI progress felt unstoppable. GPT-3 blew people away with its fluency. GPT-4 showed surprising reasoning. Today, ChatGPT-5, Claude 4 Opus, and Gemini 2.5 systems are capable of sophisticated reasoning, multilingual fluency, and even multimodal interaction. But take a step back, and you’ll notice the differences between them are slim (see Figure 1).
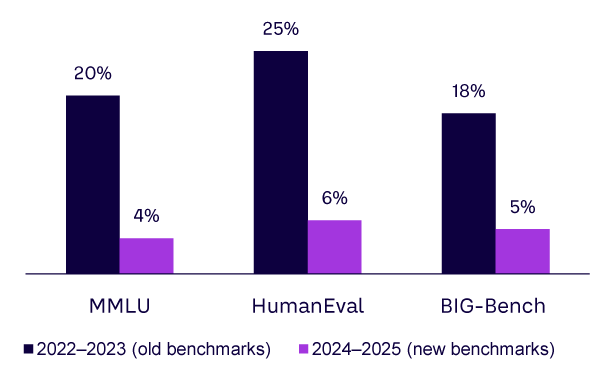
On MMLU (measuring Massive Multitask Language Understanding, a benchmark that tests AI models’ ability to answer multiple choice questions across 57 academic/professional subjects), as of September 2025, the leading models hover around 90% in terms of accuracy.2 On HumanEval, which tests coding, they differ by only a handful of points. Even open source challengers like DeepSeek function at similar levels.
The Stanford “AI Index Report 2025” notes that frontier models are converging on most static benchmarks and that incremental improvements are disproportionately costly while yielding marginal real-world value.3
Meanwhile, the leaderboards that once guided the industry are under fire. In early 2025, a tuned, nonpublic variant of Meta’s Llama 4 Maverick was submitted to the popular Chatbot Arena, where models are ranked via human head-to-head voting. It scored far higher than the released model, sparking accusations of benchmark gaming and forcing Arena’s operators to tighten policies.4,5 Researchers have warned of the “leaderboard illusion” (also known as Goodhart’s Law): once a measure becomes the target, it stops being a good measure.6 Benchmarks were once a proxy for progress. Now they’re often little more than marketing theater.
Why the Taco Bell Story Matters
The 18,000 water cup fiasco makes for easy laughs. But it demonstrates something important: AI often fails not on capability, but on context.
Look at what went wrong:
-
Norms failure. The system didn’t realize that the ask was unlikely to be the result of a genuine need.
-
Data check failure. AI didn’t know that 18,000 was absurd given the store’s inventory.
-
Workflow failure. The order was accepted by the POS system without guardrails.
-
Governance failure. No escalation was triggered before the blunder reached a paying customer.
And although funny in a fast-food setting, the same pattern can be devastating elsewhere. For example, in 2024, Air Canada’s chatbot misinformed a customer about how to access a bereavement discount. A Canadian tribunal sided with the passenger, rejecting the argument that the chatbot was a “separate entity.”7
It’s certainly easy to imagine many such missteps in implementation. If an HR recruitment bot, for example, isn’t integrated with the corporate calendar system, it could easily schedule overlapping interviews, leaving recruiters scrambling, candidates frustrated, and the company’s brand at risk.8
These aren’t failures of intelligence. They’re failures of proximity — when AI isn’t properly tethered to the data, processes, or rules of the organizations deploying it.
Cracks in Benchmark Thinking
These examples illustrate why we can’t rely on benchmarks to guide real-world adoption.9 Traditional benchmarks are:
-
Static. Sets like MMLU quickly saturate; new models simply memorize leaked questions.
-
Narrow. They test abstract skills but not organizational integration.
-
Gameable. Vendors can optimize leaderboard scores without real improvement.
-
Biased. Many leaderboards now use large language models as judges, introducing circularity.
Efforts to fix this include MMLU-Pro (harder reasoning tasks), LiveBench (dynamic, contamination-resistant), SWE-bench-Live (real GitHub issues), and ARC-AGI-2 (AI hard-reasoning problems). These are valuable, but they still don’t measure whether an AI can appropriately deal with someone ordering 18,000 waters at a drive-through.
The New Benchmark: Proximity
To move beyond the plateau, organizations need a new lens: proximity. If the models themselves (GPT-5, Claude 4 Opus, Gemini 2.5) are functionally equivalent, their performance should not be evaluated outside the context of what they are tasked to achieve. The real competitive edge lies in how closely you can align them with your business.
Four layers matter most:
-
Norms proximity. Can the AI enforce guardrails to assess the appropriateness of requests it receives, as well as the responses it produces, against a backdrop of societal and business norms that a human would be expected to abide by, naturally or after training?
-
Data proximity. Can the AI access and use your proprietary data and knowledge? How quickly do new updates show up? How well is data protected?
-
Workflow proximity. Can the AI be embedded to reliably execute tasks that are part of wider workflows or collaborations in a truly beneficial way? Does it save time and reduce human error?
-
Governance proximity. Are you able to know when the AI hallucinates or breaks policy, and are mechanisms in place to escalate safely? Can you predict and manage cost?
The Missing Piece
There’s one more piece: accountability through weighted explainability and oversight.
The phenomenon of algorithmic aversion describes how people often judge machine errors more harshly than human mistakes. The higher the stakes and the more autonomous the system, the sharper this reaction becomes. It’s the driverless car problem all over again: even if the technology is statistically safer overall, a single failure can shatter public trust. At the core of this reaction lies a perceived accountability gap, fueled by the lack of transparency in algorithmic decision-making.
When a human errs, we can ask why, assign responsibility, and expect accountability. That’s why most people accept the risk of a barista mishearing their coffee order but balk when an algorithm makes a comparable mistake (especially in contexts that feel more consequential).
Both weighted explainability (explainability that is tied to the gravity of the potential consequences of a decision) and weighted oversight (which decides when a human must be put back in the loop based on such potential consequences) are fundamental for trust and adoption.
Without them:
-
Employees won’t trust the AI’s decisions.10
-
Regulators won’t approve opaque systems.
-
Customers won’t forgive errors they can’t understand or feel empowered to challenge them.
That’s why weighted explainability and oversight are the enablers of the fifth layer of proximity: accountability proximity.
How Does Accountability Proximity Help?
To answer this, let’s go back to some of our previous examples:
-
In Taco Bell’s case, norms themselves could have sufficed to correctly qualify the nature of the request. And if this had not been enough, correct integration with inventory data, or into a workflow with input data validation, would have caught it. In both cases, the system should have been able not only to reject the request but also explain why, giving the customer the ability to reframe it.
-
In Air Canada’s case, it is the proximity to the data that was the problem. What made things worse was the inability to explain why a key part of the company’s discount terms and conditions had been ignored or misunderstood.
Each case highlights the same truth: these aren’t failures of intelligence, but failures of proximity and accountability.
AI in the Post-Benchmark Era
The era of obsessing over raw model performance is over. The marginal differences between GPT-5, Claude 4 Opus, Gemini 2.5, and the best open source challengers matter less than whether or not a system delivers measurable, reliable outcomes.
CXOs now ask: Did AI reduce our ticket backlog? Did it improve customer experience without adding risk? Can it explain itself to regulators?
This is the rise of evaluation operations: continuous, production-aligned testing that measures AI against business KPIs rather than trivia sets. Offline testing leads to shadow deployments, then live A/B tests, then full production with ongoing monitoring.
The Stanford AI Index 2025 underscores this shift: enterprise adoption increasingly depends on integration efficiency, explainability, and outcome alignment — not leaderboard scores.
The Proximity Scorecard
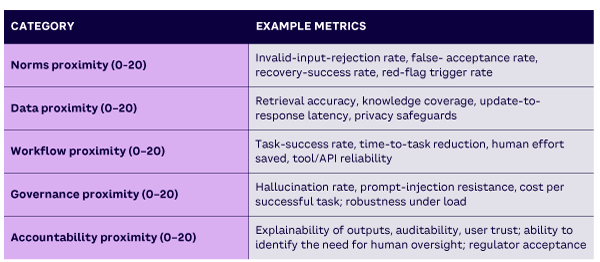
Table 1 shows a practical framework for evaluating AI readiness. Each category is worth up to 20 points, for a total of 100.
This shifts the focus from “Can the model ace a benchmark?” to “Can it deliver measurable, reliable, and sustainable value in your actual workflows?”
Conclusion: From Benchmarks to Business Outcomes
The Taco Bell glitch is prophetic. It shows what happens when an AI’s linguistic horsepower isn’t tethered to real-world context and accountability. Benchmarks are plateauing, leaderboards are being gamed, and explainability has emerged as a make-or-break factor in adoption.
The organizations that win going forward won’t be the ones chasing a percentage point on MMLU. They’ll focus on proximity and explainability — embedding AI into their norms, data, workflows, and governance while ensuring people can trust its decisions.
Those that succeed will quietly unlock massive productivity gains; those that don’t may find themselves the subject of the next viral story about an AI glitch. And no one wants to be remembered for that.
References
1 Kaplan, Zach. “Taco Bell Re-Evaluating Plans for AI Drive-Through Experience.” NewsNation, 28 August 2025.
2 “MMLU.” Kaggle, accessed 2025.
3 “Artificial Intelligence Index Report 2025.” Stanford Institute for Human-Centered AI (HAI), 2025.
4 Mann, Tobias. “Meta Accused of Llama 4 Bait-and-Switch to Juice AI Benchmark Rank.” The Register, 8 April 2025.
5 “LMArena Tightens Rules After Llama-4 Incident.” Digwatch, 9 April 2025.
6 Singh, Shivalika, et al. “The Leaderboard Illusion.” arXiv preprint, 12 May 2025.
7 Proctor, Jason. “Air Canada Found Liable for Chatbot’s Bad Advice on Plane Tickets.” CBC, 15 February 2024.
8 For an example of an AI sales agent struggling with scheduling, see Joe Allen’s article in this issue of Amplify: “Why Judgment, Not Accuracy, Will Decide the Future of Agentic AI.”
9 Eriksson, Maria, et al. “Can We Trust AI Benchmarks? An Interdisciplinary Review of Current Issues in AI Evaluation.” arXiv preprint, 25 May 2025.
10 Byrum, Joseph. “AI’s Impact on Expertise.” Amplify, Vol. 38, No. 5, 2025.


