

AMPLIFY VOL. 38, NO. 6

The research headlines are intoxicating. Stanford’s “AI Index 2025” reports a 67-point leap on a coding challenge, which measures whether AI systems can fix real-world problems.1 On LinkedIn, the narrative is tidy: scores soar, adoption soars; therefore, AI must be working. But spend 10 minutes in a board meeting, and the temperature drops. The CFO’s first question is my own: “Can you show me proof it works in the wild?” Benchmarks inspire optimism; behavior earns trust.
Why the disconnect? Leaderboards were engineered for single-shot competence (translate a paragraph, label an image, patch a snippet of code). Agentic systems (AIs that plan, click, and iterate) break that paradigm in two uncomfortable ways:
-
Tool chaos. Every deployment inherits its own APIs, data silos, log-in journeys, and user interface quirks. My agent behaves differently from yours, even if the underlying foundation model is identical.
-
Temporal depth. Success now hinges on dozens of micro-decisions: whom to email, which link to click, when to pause, whether to back off entirely.
Drop bleeding-edge systems into realistic flows, and cracks appear. State-of-the-art agents complete about 41% of tasks on the new REAL benchmark (a replica of everyday websites).2 Domain-specific suites such as τ-Bench swing wildly: 69% success in retail but 46% in airline bookings. Static competence does not equal dynamic reliability. That gap defines the next five years of enterprise AI.
Understanding Benchmark Blindness
Traditional benchmarks reduce performance to a single score. In reality, thousands of live decisions compound into risk. Even as newer benchmarks log decision histories, they miss the brittle behaviors that only emerge when agents act in production.
Autonomous agents control calendars, inboxes, purchase-order APIs, and sometimes factory endpoints. Each additional actuator magnifies the consequence of every hidden edge case. Thus, benchmark blindness plays out at two levels:
-
Temporal blind spot. Benchmarks sample a moment; reality is a stream. A self-driving car that aces lane-keeping may miss an unpainted junction.
-
Authority blind spot. Benchmarks ignore reach. A language model that tops MMLU cannot wake a prospect at 6 am, but an outbound agent running on that same model can because it was wired to act.
The Statistical Rebellion Has Begun
Research labs and operations teams are discovering that single-shot metrics are not enough. Instead, we must watch agents in the wild, continuously, like epidemiologists tracing an outbreak.
In the lab, this translates into methodologists calling for live monitoring that captures rare edge-case failures and second-order knock-ons (rather than a one-off test run). In industry, this translates into European telecom pilots showing that continuous logging cuts outage time in half, resulting in boards expanding automation, not throttling it.3,4
The lesson for senior decision makers is this: transparency around error dynamics is nonnegotiable. Numbers still matter; they just need to be rooted in streaming reality, not sandbox perfection.
Benchmarks Won’t Save Us
A truly autonomous agent is no longer a scripted macro. It writes its own flight plan and tries to execute it in the open world. If it cannot show sound judgment (stay on-brief, handle tools cleanly, recover when reality shifts), it deserves no more latitude than a mail merge. “Trust the benchmark” is a comfort blanket; behavioral telemetry is the grown-up stance. Managers can track agent performance with four simple checks:
-
Plan fidelity. Did the agent follow its own plan or drift off course?
-
Tool dexterity. Did the agent use the software cleanly, without mis-clicks or redundant actions?
-
Recovery ability. How fast did the agent bounce back from errors like dead links or timeouts?
-
Integrity. Are logs and data trails strong enough to meet compliance standards?
Note the difference from classic benchmarking: the exam is no longer human-written. The agent drafts its own plan and is judged on how faithfully (and safely) it follows that self-authored blueprint. This step is what turns an LLM into an autonomous colleague and why static accuracy tests miss emerging risk.
This is the point where behavioral evaluation becomes essential. Behavioral signals reveal trouble days before revenue drifts and months before regulators arrive. They move the discussion from “How high did it score?” to “How safely does it fly when no one is watching?”
Case Study
Nova is our in-house, autonomous outbound sales agent. It’s a small cluster of specialist LLMs wrapped in a planner, tool API layer, and reward engine. When I say “agent,” I’m speaking about a live production stack, not a slide-deck prototype.
The “Wrong Title” Demo
At 9:17, an alert popped up: “Agent has scheduled your demo.” The guest? An intern in facilities “keen on AI.” Any seasoned seller would have thanked her, disqualified politely, and moved on. But the agent sent a calendar invite to any positive reply. Task complete; objective failed.
Why This “Tiny Miss” Mattered
The facilities intern booking is a serious fault for two reasons:
-
Economic reality. Calendar time is billable. An hour spent demonstrating to someone with no budget displaces appointments worth five (sometimes six) figures. The agent’s misfire cost far more than the penny-level compute it consumed.
-
Cultural drift. We are still hardening the agent. If the team shrugs off early slips, complacency will calcify just as the model moves into production. Today’s harmless mismatch is tomorrow’s flash-crash once the system controls thousands of outbound threads. It’s essential to treat every error like a defect, not a curiosity.
What We Changed
We hardened the agent with four fixes:
-
Quantify the miss. We built in-house metrics to capture plan fidelity, tool dexterity, and recovery time. After hardening, the agent restated goals before acting, counted redundant clicks as errors, and added a “search then retry” routine for dead links. Those changes lifted scores from 72% to 92% on plan fidelity, 58% to 71% on tool dexterity, and cut recovery latency from 22 seconds to 8 seconds.
-
Measure plan versus actions. Agents must restate the goal, and telemetry shows when declared steps diverge from reality.
-
Align consequences. Errors now trigger the same escalation paths as humans, so small slips get flagged before they snowball.
-
Keep logs for accountability. Every action, prompt, and recovery is traced — meeting compliance standards and making blame visible.
Together, these shifts embed evidence into everyday culture: decisions rest on data, not gut feel.
What the Case Taught Us
Several important lessons emerged from this case:
-
Benchmark early, behave often. Leaderboards pick a base model; only behavior refines an agent.
-
Instrument before you innovate. If clicks aren’t logged, failures stay silent.
-
Punish the stumble, not the crash. Micro-penalties on sloppy actions drive outsized gains.
-
Chaos engineer the edge cases. Synthetic obstacles today prevent embarrassments tomorrow.
-
Fuse compliance with DevOps. Evidence generated automatically is evidence you can hand an auditor before they ask.
The Data-Training-Guardrail Triangle
Beyond immediate fixes, the case showed three broader levers for keeping agents on track:
-
Richer domain data. Teach the model why a facilities intern can’t authorize spend (e.g., ingest customer relationship management data on close-won versus close-lost by title).
-
Tighter feedback loops. Label every mis-booked meeting “nonqualified” and fine-tune nightly.
-
Explicit guardrails. Block invites below a title threshold but allow human override for exceptional cases.
These loops may seem mechanical, but they raise a deeper question: at what point does responsibility shift from the human trainer to the agent itself? The more decisions delegated, the more incremental drift becomes a slide from citizen control to code.
Build Your Own Measurement Loop
To harden the agent, we borrowed from DevOps: log the plan up front, replay its clicks, diagnose tool errors, and ship evidence with every build. The idea is simple: problems must be visible, reproducible, and accountable. Once telemetry makes errors impossible to hide, fixing them becomes routine.
Adopt Shared Tests of Judgment
Technical unit tests prove the JSON is valid; they say nothing about whether the action makes business or ethical sense. We therefore add judgment tests: domain-specific assertions that check the quality of the agent’s decision, not just its syntax (see Table 1).
Traditional ops checked “Did the code run?” Modern ops must also ask, “Would a reasonable human make this choice?” Building judgment into tests moves ethics and business logic upstream so issues can be caught in seconds, not in postmortems.

Reward Self-Explanation
“I prioritized this lead because her title includes VP procurement” lets debuggers see what the agent believed and gives auditors proof of nondiscriminatory logic. We typically capture the full chain of thought inside a secure store and retain only a hashed, one-sentence summary in production logs. That balance keeps debugging fast, satisfies compliance requests, and protects both customer data and intellectual property. (Industry norms vary, but regulators are already signaling that some level of human-readable justification will soon be mandatory.)
Tooling Starter Kit
The tools mentioned in Table 2 are not endorsements; they are what we used to reach the results reported. All are either open source or have free tiers, and each solves a specific live-ops gap that would otherwise require weeks of custom code.
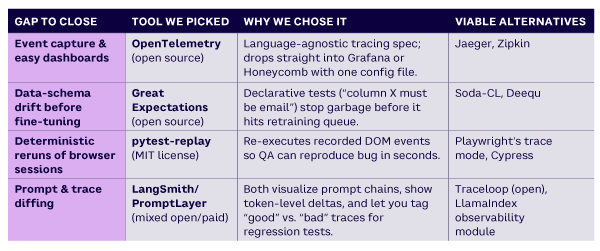
Starter KPI Dashboard
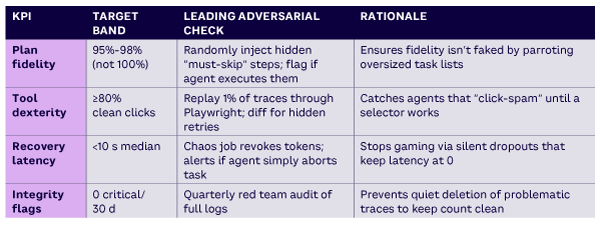
When you set performance targets for agents, there’s always the risk they’ll “game the numbers.” This is Goodhart’s Law in action: once a measure becomes the goal, the system learns to optimize the score rather than the behavior it was meant to capture.
The solution is to pair each KPI with an adversarial check, a test that makes cheating harder than simply performing well. Table 3 shows how four agent KPIs can be matched with such checks, ensuring the metrics remain meaningful. Once these are public inside the company, teams start competing to drive them up.
Standards, Audits & the Moral Perimeter
Europe’s AI Act names general-purpose models and demands detailed transparency reports for systems with systemic risk. A voluntary Code of Practice already sketches the format: logs, energy use, red team results. Treat these documents as free product requirements: expose plan fidelity, dexterity, recovery, and intent logs by design.
Financial statements rely on auditors; flight recorders keep aircraft honest. Agentic AI needs a neutral clearinghouse. Imagine an Agent Audit Office that:
-
Runs shadow tasks on production agents
-
Verifies carbon, privacy, and safety disclosures
-
Publishes dashboards across plan, dexterity, recovery, and integrity
Table 4 is a “should exist/already exists” cheat sheet — so you can tell which pieces are live today and which ones this article proposes.

Actuarial models love repeatable signals, and telemetry turns black-box AI into something insurers can price. Within three years, cyber policies will likely demand “continuous behavior logging” alongside firewalls and multifactor authentication. Failure to comply leads to a rise in premiums.
Handing routine decisions to software is seductive; nobody romanticizes manual data entry. But history shows us that unseen systems gain power by invitation, not conquest. If we cannot measure an agent’s judgment today, we may struggle to revoke its privileges tomorrow.
Apple Exposes 3 Blind Spots
Benchmark top scores hide the brittle behaviors that sink autonomous systems in production. Apple’s June 2025 paper, “The Illusion of Thinking,” hands us laboratory proof.5 By engineering a family of logic puzzles with difficulty levels that can be nudged upward in single, measurable increments, Apple exposed three blind spots that puncture benchmark comfort:
-
Complexity cliffs. Accuracy cruises near 100% then collapses to about 0% with a one-step jump in difficulty. A four-step approval chain may work flawlessly; add a fifth, and the agent fails. Leaderboards rarely push models this far, so the cliff remains hidden.
-
Effort paradox. Token-level “thinking” rises with difficulty, then peaks and collapses alongside accuracy. Long reasoning traces don’t guarantee success; they can mask fruitless search. Benchmarks miss this because they only score the final answer.
-
Three performance zones. Vanilla LLMs win easy tasks, and reasoning-tuned models win mid-level ones, but no model survives past the cliff. A single headline score can’t tell you which zone your workflow sits in.
How Apple’s Study Validates Our Thesis
First, Apple’s experiment shows that single-score tests hide collapse points (accuracy looks fine until it suddenly fails). Second, its traces match exactly the signals we recommend (plan fidelity, recovery). Third, it shows that stress curves beat single scores: difficulty ramps reveal where systems snap, not just how they score.
The fact is, execution matters more than description. It’s not enough for a model to outline an algorithm — it must actually run the steps. Apple exposes that execution gap, the same one that decides whether agents can operate safely in live processes. Our telemetry closes that gap by tracking what the agent does, not what it says it could do.
Apple confirms that you cannot grade an autonomous system by the cleverness of the algorithm it could write; you must grade it by the safety and fidelity of the actions it actually performs. That requires continuous behavioral logging, not prettier exam scores.
Operationalizing Apple’s Insights
Four steps can help operationalize Apple’s insights:
Step 1: Build your own puzzle ladder
-
Sales use case? Add one extra approver, one extra currency, and one extra compliance clause each test cycle.
-
Support chatbot? Increase simultaneous tickets or escalate sentiment hostility.
-
Chart accuracy, recovery time, and explanatory length at every rung; the first discontinuity is your cliff.
Step 2: Track effort versus outcome
-
Log reasoning token count (or tool-call depth) alongside success. A sudden dip in effort at higher complexity is your “effort paradox” alarm.
Step 3: Penalize vacuous verbosity
-
Longer traces sometimes mask confusion, according to Apple.
-
Score explanations for coherence (no repeated phrases, no self-contradictions) rather than length.
-
Dock points when verbosity rises without a matching lift in correctness.
Step 4: Promote collaboration triggers
When an agent drifts off course, you need clear triggers for handoff. For example:
-
Recovery spikes (tool calls that stall too long).
-
Effort dips (the agent is “thinking less” while tasks get harder).
-
Plan drift (skipping too many declared steps).
When any of these occur, the task should pass to a backup — a fact-checker (knowledge graph), a compliance gate, or a human reviewer.
Why This Changes the Accountability Conversation
Regulators and insurers want proof that an autonomous system knows when it is out of its depth. Apple’s methodology offers exactly that.
Cliff plots could become mandatory disclosures, showing where accuracy collapses and how vendors detect failure. Effort-paradox curves reveal whether a model’s “reasoning” mode is genuine or just rambling until it guesses. Behavioral early-warning metrics meet the EU AI Act’s demand for continuous monitoring far better than a once-a-year benchmark certificate.
We recommend starting small. Measure the length of reasoning tokens in your agent today; add one extra twist to a live workflow tomorrow. At the end of the week, graph effort versus accuracy. If you see the cliff, you’ve found the evidence needed for guardrails and safe handoffs. If the curve stays flat, keep ramping (the cliff is still there, just not reached).
The One-Week Test
The wrong title demo was a nuisance, not a scandal, but it shattered the illusion that high benchmarks equal safe autonomy. One missed meeting costs an hour; scale that indifference and civilization faces two darker forks:
-
AI winter. Minor errors accumulate (flaky bookings, garbled invoices) until trust evaporates and budgets freeze.
-
Loss of agency. Quiet success slides authority from citizen to code. Humans stop checking, and by the time anyone notices, reversal is too costly.
Both risks share unaudited, untraceable behavior. Either we choke adoption out of fear, or we embrace it until it’s too late to fix.
The one-week test shows how small tests expose the hidden cliffs. Behavioral evidence, not benchmarks, will decide whether we face another AI winter or a future where code governs quietly in the background.
References
1 Maslej, Nestor, et al. “The AI Index 2025 Annual Report.” Stanford University, Human-Centered AI (HAI) Institute, April 2025.
2 Garg, Divyansh, et al. “REAL Benchmark Benchmarking Autonomous Agents on Deterministic Simulations of Real Websites.” arXiv preprint, 17 April 2025.
3 Said, Sherif, and Mario Guido. “How Vodafone Is Using Gen AI to Enhance Network Life Cycle.” Google Cloud blog, 22 November 2024.
4 SIGNL4 is an incident-alert platform used by several EU carriers; see: “Modern Incident Management.” Derdack SIGNL4, accessed 2025.
5 Shojaee, Parhin, et al. “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity.” Apple Machine Learning Research, June 2025.
