

Big data storage needs to do more than merely provide storage; it needs to offer mechanisms for data analytics. Such analytics utilize existing organizational (typically transactional) data together with data available from NoSQL databases. According to Cutter Consortium Senior Consultant Curt Hall, “High-performance analytic databases offer organizations a way to supercharge their existing DW [data warehouse] environments by offloading and accelerating high-demand and/or complex analytic processing.” Figure 1 summarizes the complexities of handling such big data–based analytical processing.
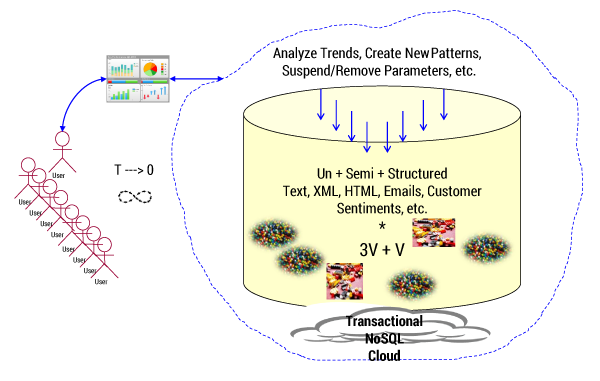
real-time analytics, location independence, security, and privacy.
The large volumes and velocity of data are coupled with large numbers of users seeking their own personalized services at the time and location of their choosing. Timely performance of analytics in a secured manner with due respect to privacy adds to the challenges of big data storage. And these are not merely technical challenges. The moment the focus shifts from mere storage of data to generating business value, the data management challenges multiply. The data management challenges are as follows:
-
Data availability across applications. Databases are judged principally on their ability to handle the volume, velocity, and variety of data. Hadoop-based infrastructure provides almost limitless, inexpensive data storage space in the cloud. But simply handling large volumes is not enough. Big data storage systems need to respond to demand for fast-paced and fine-granular analytics and the corresponding applications. For example, these databases need to make available high-velocity (frequency) data (e.g., stock market trading data), sensor data (e.g., generated by the Internet of Things [IoT] and machines), and biometric data (e.g., retina and fingerprint scans) for myriad applications.
-
Handling mobile data. Mobile applications generate high-volume, high-velocity data and also need continuous availability of data that can be processed quickly and effectively. Data stores need to keep up with both incoming storage and outgoing provisioning of data over cellular networks.
-
Handling IoT- and machine-generated data. Semistructured or unstructured data generated by devices mostly without human intervention results in high volume and velocity and needs to be securely sourced and stored without benefit of a definition or schema. Furthermore, the metadata associated with IoT and mobile data needs to be logged and made available for the purpose of traceability and processing.
-
Handling unstructured data. The majority of big data is unstructured, including large, free-formatted text and numbers, as well as audio and video files. Data storage mechanisms for big data need to have associated data-handling tools that enable ease of data extraction and ease of transfer and associated processing. Innovative approaches in handling unstructured (or schema-less) data are needed. Handling schema-less data requires data storage tools that enable searches and manipulation of such unstructured data.
-
Supporting large numbers of concurrent and diverse users. Users may be internal (staff within the organization) and/or external (customers, partners); SoMo can lead to a rapid increase in the number of users. These users demand instantaneous access to data and correspondingly fast analytics. Data stores need to be equipped to identify these users, scale up to meet their growing demands, and be flexible enough to accept their varying numbers.
-
Handling storage in the cloud. Data storage mechanisms need to be based on the understanding that almost all organizational data is now moving to the cloud. Although there may be regulatory requirements around the security and privacy of data, most such data is in the cloud. Therefore, cloud storage is integral to any approach to managing big data.
-
Needing rapid visualizations. Social media and mobile users demand rapid presentations (visualizations and dashboards). Supporting these users in real time requires that data storage be sufficiently fast and responsive.
-
Integrating with structured data. Existing enterprise data (mostly transactional) is organized in relational structures of columns and rows accompanied by keys and constraints. In order to provide practical business insights, this structured and transactional data has to be combined with the rapidly incoming semistructured and unstructured data. There is “friction” between the schema-based rows and columns (that are difficult to change) and the schema-less big data that is difficult to organize. Data management must factor in the need to merge data types to enable integrated processing.
-
Providing data to a large number of external applications. Data management is not limited to handling only the data owned by the organization within the organization. In a collaborative big data world, there is a need to also provide data to external parties. These external parties can be third-party users and applications, whether compliance agencies instituted by governments or open data initiatives that require data and metadata.
-
Veracity of data. The greater the volume of data, the more difficult it is to ensure its quality. An additional veracity (aka the fourth V) challenge with big data is that the sources of the data cannot always be verified (e.g., crowdsourced data).
- Data availability across applications. Databases are judged principally on their ability to handle the volume, velocity, and variety of data. Hadoop-based infrastructure provides almost limitless, inexpensive data storage space in the cloud. But simply handling large volumes is not enough. Big data storage systems need to respond to demand for fast-paced and fine-granular analytics and the corresponding applications. For example, these databases need to make available high-velocity (frequency) data (e.g., stock market trading data), sensor data (e.g., generated by the Internet of Things and machines), and biometric data (e.g., retina and fingerprint scans) for myriad applications.
[For more from the author on this topic, see “Big Data and NoSQL: Business Opportunities Beyond Storage and Retrieval.”]
