

AMPLIFY VOL. 38, NO. 6

Part I of this two-part Amplify series on disciplining AI considered criteria for AI success across industries and social domains.1 Here in Part II, we closely examine how to evaluate against one’s criteria when building and governing AI systems.
In the short time since Part I was published, concerns have continued to be raised about AI's application in the real world. Consumer safety is one aspect.2 In an especially troubling case, the parents of a teenager who died by suicide under advice from ChatGPT are suing OpenAI, with OpenAI already acknowledging flaws in its chatbot’s guardrails.3
In the enterprise context, recently released preliminary findings from an MIT report (the latest in a string of surveys showing troubles with AI adoption) suggest 95% of organizations that invested in generative AI (GenAI) over the past three years have yet to see a positive ROI.4
Both GenAI model performance and enterprise adoption appear to be plateauing.5 The former was exemplified for many by the launch in August of GPT-5, with intelligence gains that initially appeared modest compared to both the hype and previous major model releases. The past few months have been dubbed by some as AI’s “cruel summer.”6
Speculation that the AI bubble might be bursting has intensified, but the technology won’t necessarily be leaving us here on our own (to paraphrase Bananarama’s pop music hit “Cruel Summer”). Hype cycles are well understood, and many core technologies have been through one.
AI could continue to improve as one technology among many, essential for some tasks, complementary for others, but a long way from transcending into artificial general intelligence or superintelligence.7 Self-styled AI realists argue that the route to the latter will be through more composite approaches and not through reliance on large language models (LLMs), which will also require commercial adjustment.8
If GenAI is going to remain fallible for the foreseeable future and exist as a component in a complex system, then oversight of its outputs is vital. This is by no means just about policing the AI’s bad behavior; it’s about unlocking real value in situ. It is illustrative that, after initial disappointment, GPT-5 appears to be held in increasingly high regard (see Figure 1). Progress is not always apparent at first glance; truly productive applications sometimes require adaptation and localization.
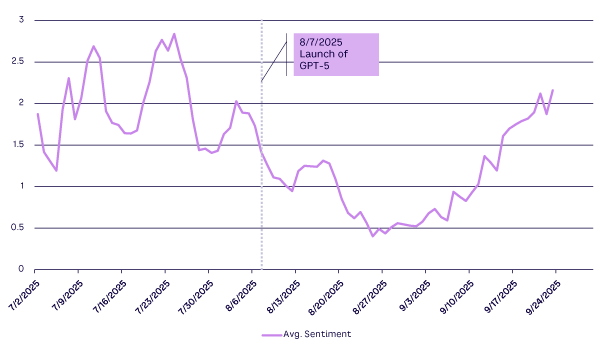
This does not occur naturally. According to the previously mentioned MIT report, a key differentiator between successful and stalled GenAI pilots is the capacity of the pilot system to learn and improve in response to feedback, as well as to dynamically adapt to context.9 Part I of this Amplify series showed us that oversight can be complex and that context can be varied.
In This Issue
The contributors to this second issue explore what we’re trying to do when we systematically evaluate AI systems and look at some of the philosophical-technical challenges and solutions involved.
Frequent Amplify contributor Paul Clermont opens the issue by reminding us of a crucial but under-recognized trait of true AI: learning and improvement in response to feedback independent of explicit human design. The implementation of human requirements is thus both highly feasible and dialogic. Clermont stresses the high level of responsibility borne by humans when interacting with AI. Critical thinking about inputs and outputs, and awareness of both objectives and social context, remain firmly human (and sometimes regulatory) responsibilities — no matter how widely terms like “AI accountability” have gained currency.
How can we ensure accountability for AI systems, especially as they scale and grow more complex? Looking specifically at LLMs, my Arthur D. Little (ADL) colleague Dan North examines the engineering discipline of AI evaluations, arguing that this is the locus of an LLM’s translation from task-agnostic capabilities measured by benchmarks to tech that is setting specific and ready-to-deliver success. He emphasizes the ultimately human nature of this discipline. An organization must define the kind of outputs it is looking for through an inclusive process involving customers and stakeholders, alongside engineers.10
Such definition may be far from simple. For complex AI systems, the nature of the required output may differ markedly from step to step, and this might not be apparent “above the hood.” AI can provide support by generating test data and evaluating LLM outputs against criteria, but without informed, judicious human involvement, there are no meaningful criteria.
My ADL colleagues Michael Papadopoulos, Olivier Pilot, and I agree that with model performance plateauing, the critical differentiator for AI in 2025 is how the technology is integrated into the specifics of an organization — and the context in which it will operate. Benchmarking, which is concerned with models out of context, is of diminishing applicability.
After reviewing some entertaining but troubling examples of theoretically capable AI systems disconnecting disastrously from data, business rules, and basic plausibility, we propose an evaluation framework more attuned to contemporary challenges to prevent similar outcomes. The key properties are oversight, explainability, and proximity (to data, process, and policy). Again, evaluations play a central role in orchestrating the components of the system, holistically understood.
Next, Joe Allen joins the critique of benchmarks as the key means of measuring AI systems, with a focus on agents. Given the open world in which they operate, agents have autonomy over both planning and execution, and Allen argues they have already outgrown even the criteria used to evaluate LLMs. As self-organizing systems, agents should be assessed on their ability to follow their own plans consistently while adapting to unforeseen eventualities — an evaluation that cannot be fully scripted in advance.
Furthermore, agents are increasingly acting in the real world. Unlike in even mission-critical conventional systems, they do not behave deterministically. The stakes are thus higher in terms of risk, reward, and uncertainty. Drawing on direct experience, Allen details a suite of techniques that can be used to track and improve agent performance in terms of internal coherence, adherence to a context model, and more. The approach is iterative and continual, but that is what’s required for such a dynamic technology.
So far, the focus of this Amplify issue has been on evaluating and incrementally improving an existing AI system. Looking further ahead, how can one foresee when the entire system will no longer be enough?
In our final article, Chirag Kundalia and V. Kavida propose using survival analysis to understand when, and under what circumstances, an AI system might need maintenance or replacement. This approach involves modeling the intrinsic and extrinsic factors that could render a system no longer fit for purpose. It also requires organizations to define the standard of output the system must deliver, monitor that performance, and scan the horizon for relevant externalities (e.g., superior technology). Although survival analysis cannot anticipate every eventuality, modeling the future of an AI system enhances budgeting, compliance reporting, and strategic planning.
Key Themes
Organizations implementing AI systems must overtly define what “good” looks like. Guardrails and quality control are important — sometimes critically so — and AI evaluations are a principle means by which the organization can steer this nondeterministic technology and define its purpose for them. Confining it to an engineering subdiscipline would be a waste of a key opportunity. We might be tempted to let AI take the lead and tell us something we don’t know. This might prove beneficial when using GenAI for research or “vibe coding,” but for serious applications, one must be directive about purpose and context.
Having a framework in place to measure one’s AI system against purpose and context leverages this technology’s ability to learn and adapt without extensive rewiring. Data from evaluations can feed both into strategic planning and straight back into the AI system.
Explainability also emerges as key.11 Evaluations are greatly enriched when one can go beyond playing trial-and-error with outcomes and understand why the system behaved the way it did. This is particularly important for agents, which may be following an evolving plan they have put together themselves. Also, if a range of stakeholders is going to be involved in steering the AI system, explainability is needed for that to be an open conversation among equals.
Identifying what an organization is looking for from a system is challenging, as is integrating that system with context and making it explainable in an effective way. Multiple contributors to this Amplify issue reference Goodhart’s Law, under which well-intentioned application of metrics perverts a system’s priorities.
The challenge intensifies the more general-purpose a system is, even as the various possible purposes in any given interaction multiply, increasing the complexity of the metrics required.
The peak challenge may be posed by consumer chatbots like ChatGPT or Claude. To illustrate, a recent OpenAI paper argued that much-maligned hallucinations in LLMs arise from post-training that discourages models from admitting they don’t know and pushes them to guess instead.12
A human design decision is required as to whether what is sought is transparent caution, proactive risk-taking, or the kind of gradation of certainty that characterizes much human expression. Although not always reaching such levels of profundity, organizations should consider this kind of question when evaluating an AI system. Familiar disciplines like quality assurance, user experience research, software testing, and requirements analysis are all relevant.
Given increased responsibilities and autonomy of the systems, however, we find them remixed and applied to new questions and behaviors. The contributions presented in this issue add valuable insights into how this might be done rigorously and with cognizance of what is really needed.
Acknowledgments
Alongside the contributors and the ADL Cutter team, I would like to thank Lara Arnason, Natalie Demblon, Brian Lever, Greg Smith, and Oliver Turnbull for their thoughtful input.
References
1 Thanisch, Eystein (ed.). “Disciplining AI, Part I: Evaluation Through Industry Lenses.” Amplify, Vol. 38, No. 5, 2025.
2 Nelson, Alondra. “An ELSI for AI: Learning from Genetics to Govern Algorithms.” Science, Vol. 389, No. 6765, September 2025.
3 Yousif, Nadine. “Parents of Teenager Who Took His Own Life Sue OpenAI.” BBC, 27 August 2025.
4 Challapally, Aditya, et al. “State of AI in Business 2025.” MIT Project NANDA (Networked AI Agents in Decentralized Architecture), July 2025.
5 Kahn, Jeremy. “Is the AI Bubble About to Burst? There’s Mounting Data Suggesting It Might Be.” Fortune, 9 September 2025.
6 Nelson (see 2).
7 Narayanan, Arvind, and Sayash Kapoor. “AI as Normal Technology.” Knight First Amendment Institute at Columbia University, 15 April 2025.
8 McMahon, Bryan. “What If There’s No AGI?” The American Prospect, 4 September 2025.
9 Challapally et al. (see 4).
10 For more on how modeling intended AI outcomes brings stakeholders together, see: Farrington, Joseph. “A Simulation-First Approach to AI Development.” Amplify, Vol. 38, No. 5, 2025.
11 As shown in Part I, it is also a legal requirement in many contexts; see: Nance, Rosie, et al. “Explain Yourself: The Legal Requirements Governing Explainability.” Amplify, Vol. 38, No. 5, 2025.
12 Kalai, Adam Tauman, et al. “Why Language Models Hallucinate.” arXiv preprint, 4 September 2025.
