

AMPLIFY VOL. 36, NO. 8

“The era of global warming has ended; the era of global boiling has arrived,” comes the stark warning from United Nations Secretary-General António Guterres.1
“I knew I had just seen the most important advance in technology since the graphical user interface,” Microsoft cofounder Bill Gates wrote of seeing an early demo of ChatGPT in September 2022. “Entire industries will reorient around [artificial intelligence].”2
Will this reorientation of entire industries around powerful and power-hungry large language models (LLMs) push us deeper into global boiling? Will Stable Diffusion destabilize our climate even further? Will Google’s PaLM leave us all living in a desert? Will Meta’s newly released Llama 2 spit in the face of net zero?
Exactly how power-hungry are these models, anyway?
Modern LLMs require huge amounts of computing power to churn through huge amounts of data. Leaked estimates about GPT-4 (the latest LLM from OpenAI) put it at consuming trillions of words of text over a three-month-long training process that required up to 25,000 state-of-the-art graphics processing units (GPU) from industry leader Nvidia. OpenAI CEO Sam Altman put the monetary cost at more than US $100 million.3 The breakdown of this figure is not known, but back-of-the-envelope calculations imply that energy costs alone could account for almost $10 million.4
How much energy does the training process require? How much energy is needed to continuously serve an LLM via ChatGPT to serve billions of page views each month? How do these numbers stack up against the energy required to fly, use the oven, or stream a video?
In this article, we dissect the carbon footprint of LLMs, compare this footprint to familiar activities, highlight ways to minimize their impact, and evaluate the green credentials of some major players behind the recent wave of generative artificial intelligence (GAI).
What Is the Environmental Impact?
Environmental impacts come in many forms, but here we focus primarily on carbon dioxide equivalent (CO2e) emissions, since CO2 is the main greenhouse gas (GHG) causing global warming and the biggest threat to the environment.
The carbon emissions from an LLM primarily come from two phases: (1) the up-front cost to build the model (the training cost) and (2) the cost to operate the model on an ongoing basis (the inference cost).
The up-front costs include the emissions generated to manufacture the relevant hardware (embodied carbon) and the cost to run that hardware during the training procedure, both while the machines are operating at full capacity (dynamic computing) and while they are not (idle computing). The best estimate of the dynamic computing cost in the case of GPT-3, the model behind the original ChatGPT, is approximately 1,287,000 kWh (kilowatt-hours), or 552 tonnes (metric tons) of CO2e.
We will put this number into a fuller context in the next section, but we mention here that this figure is approximately the same emissions as two or three full Boeing 767s flying round-trip from New York City to San Francisco. Figures for the training of Llama 2 are similar: 1,273,000 kWh, with 539 tonnes of CO2e.5 Analysis of the open source model BLOOM suggests that accounting for idle computing and embodied carbon could double this requirement.6
The ongoing usage costs do not include any additional embodied carbon (e.g., from manufacturing the computers, which have been accounted for in the building cost) and are very small per query, but multiplying over the billions of monthly visits results in an aggregate impact likely far greater than the training costs.
Estimates from one study for the aggregate cost of inferences for ChatGPT over a monthly period were between 1 to 23 million kWh considering a range of scenarios, with the top end corresponding to the emissions of 175,000 residents of the author’s home country of Denmark.7 Another pair of authors arrived at 4 million kWh via a different methodology, suggesting these estimates are probably in the right ballpark.8
We note that in any event, the electricity usage of ChatGPT in inference likely surpasses the electricity usage of its training within weeks or even days. This aligns with claims from AWS and Nvidia that inference accounts for as much as 90% of the cost of large-scale AI workloads.9,10
One comment about efficiency. Continuing our earlier analogy, instead of two or three full Boeing 767s flying round-trip from New York to San Francisco, current provision of consumer LLMs may be more like a Boeing 767 carrying one passenger at a time on that same journey. For all their power, people often use the largest LLMs for relatively trivial interactions that could be handled by a smaller model or another sort of application, such as a search engine, or for interactions that arguably need not happen at all. Indeed, some not-exactly-necessary uses of ChatGPT, such as “write a biblical verse in the style of the King James Bible explaining how to remove a peanut butter sandwich from a VCR” bear more resemblance to a single-passenger flight from New York to Cancún than from New York to San Francisco.11
Excitement around GAI has produced an “arms race” between major providers like OpenAI and Google, with the goal of producing the model that can handle the widest range of possible use cases to the highest standard possible for the largest number of users. The result is overcapacity for the sake of market dominance by a single flagship model, not unlike airlines flying empty planes between pairs of airports to maintain claims on key routes in a larger network.12 The high levels of venture capital (VC) funding currently on offer in the GAI space enable providers to tolerate overcapacity for the sake of performance and growth.13 As we will discuss, business models that are much more energy- and cost-efficient are available.
We must emphasize the huge uncertainty surrounding the estimates on which this analysis is based, which stems from both lack of standard methodology and lack of transparency in the construction of LLMs. ChatGPT maker OpenAI has not publicly announced either the data used to train the model nor the number of parameters in its latest model, GPT-4. Speculation and leaks about GPT-4 put the figure at approximately 10 times the number of parameters in GPT-3, the model powering the original ChatGPT.14 Google has not released full details about the LamMDA model powering its chatbot, Bard. DeepMind, Baidu, and Anthropic have similarly declined to release full details for training their flagship LLMs.
Uncertainty remains even for open source models, since the true impact of a model involves accounting for the cost of deploying the model to an unknown and varying number of users, as well as the emissions used to produce the hardware that serves these models to end users. Still greater complexity derives from the precise mix of fossil fuels and renewable energy used where the models are trained and deployed.
Finally, we mention briefly that the water consumption of ChatGPT has been estimated at 500 milliliters for a session of 20-50 queries. Aggregating this over the billions of visitors ChatGPT has received since its launch in December 2022 amounts to billions of liters of water spent directly cooling computers and indirectly in the process of electricity generation.15
Is That Worse Than Boiling the Kettle?
Millions of kWh per month to run an LLM sounds like a lot. But how does that compare to the emissions generated by other activities, computational or otherwise?
A round-trip flight from New York City to San Francisco emits about 1 tonne of CO2e per passenger.16 So the ~500 tonnes of CO2e required to train GPT-3 equates to the emissions of approximately two or three full round-trip flights from New York City to San Francisco. Given that the world’s busiest airport, Hartsfield-Jackson Atlanta International Airport, sees an average of 1,000 departing flights per day, those 500 tonnes are relatively insignificant.
Thinking about computational activity more broadly, the information and communications technology (ICT) sector accounts for a quite significant 2%-4% of all GHG emissions globally, with a total of 1 to 2 billion tonnes CO2e per year, on par with sectors like aviation or shipping.17 By comparison, Bitcoin mining generates 21 to 53 million tonnes of CO2e per year, according to Massachusetts Institute of Technology (MIT) analysis.18 Bitcoin, of course, does not offer the same potential as LLMs to accelerate scientific discovery or alter the work of white-collar professionals worldwide.
Noting once again the difficulty of ascertaining such estimates, we cautiously assert that LLMs likely account for less than half a percent of emissions from the entire ICT sector and less than 0.01% of global emissions. Indeed, global annual GHG emissions in CO2e have hovered above 50 billion tonnes annually since 2010.19 Even if inference uses 100 times as much as training, and even if there are 100 models as popular as ChatGPT, these LLMs still account for only 5 million tonnes CO2e (100 x 100 x 500 = 5 million): 0.01% of global emissions or at most half a percent of global ICT emissions.
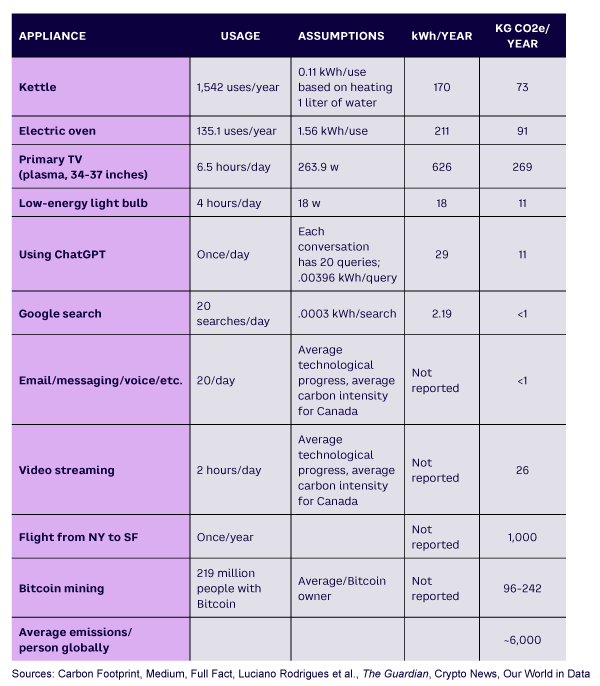
Table 1 shows how using ChatGPT compares to other daily activities. To compare the environmental impact of different activities, we use two metrics. The first is the electricity required, in kWh. The downside of this metric is that many important processes (such as airplanes) do not run on electricity, so we need to consider another metric. The second yardstick is CO2e emissions. This allows us to compare electric with nonelectric uses of energy, so it’s a truer reflection of the environmental cost, but the cost of doing the same activity (e.g., powering a laptop) varies tremendously depending on the precise mix of fossil fuel and renewable energy sources where the laptop is plugged in. Note that we have only one of these metrics for some of the entries.
A Sustainable Future for GAI
Whatever the environmental impact of LLMs, all players can reduce it by improving the location and time of training, model size, transparency, and hardware efficiency. Machine learning engineers can make improvements on any data science project by optimizing algorithms for computational efficiency or by carbon profiling,20,21 data leaders can empower them to train in times and places with low-carbon energy available, and LLM providers can enable carbon budgeting by being more transparent about emissions associated with their models.
Other approaches are more strategic and call for a fundamental restructuring of how GAI is currently done. LLMs first came to widespread public attention via services like ChatGPT. In this model, a well-funded tech company trains a very large LLM to handle a wide range of tasks and serves it at scale as a cloud-based chatbot to a general user base.
An alternative business model would be for AI vendors to train much smaller LLMs for specific categories of tasks.22 Specialist companies or teams would fine-tune as needed on dedicated data sets for specific use cases — that is, they would modify a model by updating a few relevant parameters. For additional efficiency, engineers can quantize models: reduce the model parameters’ theoretical precision without sacrificing overall accuracy.
Such approaches can slash the computational cost of producing a fit-for-purpose LLM. In a seminal study of quantized fine-tuning,23 some Guanaco models less than half the size of ChatGPT achieved more than 97% of the latter’s performance on certain tasks with as little as 12 hours fine-tuning on a single GPU. Compare this to the purported 25,000 GPUs required to train GPT-4.
In addition to making LLMs more environmentally sustainable, this approach empowers users to harness the power of GAI for specific objectives, even those without AI engineering skills — watch for no-code fine-tuning already coming online.24 With emphases on transparency and user empowerment, efforts to make LLMs environmentally sustainable also happen to align with efforts to keep it democratic.25 The small-but-many-models approach may also be the best way to continue advancing the technology, with Altman himself stating that the returns from increasing the size of models will soon begin to diminish.26
GAI shares many of the same challenges as AI and computing more generally. Data centers, storage, memory, GPUs, and so on, underlie modern computing as a whole, not just LLMs. Historically, data centers have been able to offset increases in computational demand through increased efficiency; energy required per computation in data centers decreased by 20% between 2010–2018.27
Although there is debate over how long this will continue at the level of hardware, Koomey’s law suggests the computational efficiency of GPUs will continue to double every couple of years over at least the medium term,28 and such developments would reduce carbon emissions for anything running on GPUs, including LLMs. Blockchain, for all its sins, presents an optimistic analogy. Bitcoin specifically may deserve the blame for huge carbon emissions, but the underlying technology is evolving in more sustainable directions. The increasingly adopted proof-of-stake consensus mechanism, for example, can be orders of magnitude less costly than the Bitcoin proof-of-work consensus mechanism in terms of energy consumption.29
Who will ensure the ongoing sustainability of GAI or computing more broadly? The combination of VC incentives to grow with difficulties regulating Big Tech may prove challenging for sustainability efforts. Indeed, the VC-driven push to grow at all costs runs directly counter to a desire for environmental efficiency.
Nevertheless, we believe that explicitly monitoring energy efficiency in meeting a specific user need (or the energy efficiency of the overarching models) would help keep financial incentives aligned with sustainability. Such efforts have already paid dividends in the automobile industry, where fuel efficiency of American cars approximately doubled between the introduction of Corporate Average Fuel Economy standards in 1975 and 1985,30 with President Obama–era regulations driving efficiency ever higher through the 2010s.
Following the money helps us identify where to focus such pressure, regulatory or otherwise. Leading Silicon Valley venture firm Andreessen Horowitz points to hardware and infrastructure providers (Nvidia and AWS/Google Cloud/Microsoft Azure, respectively) as currently claiming the lion’s share of the profits, with the widest moat as well, not the model-providers themselves.31
Speaking of moats, a widely circulated memo from a Google employee agrees that the models do not provide a moat for Google or for OpenAI.32 Given that venture capitalists often push for growth and more growth, rather than sustainability, and given that the tech giants are greener than most other big companies (see below), have deep pockets, and are seemingly more susceptible to social pressure, perhaps regulators and consumers can most productively focus pressure on the likes of AWS and Nvidia.
As a final side note, following the money trail even further reveals Taiwan Semiconductor Manufacturing Company chips underpinning all these other giants,33 which highlights the geopolitical risk to a truly sustainable existence for all kinds of computing, at least in the West.
Tech Giants Greener Than Most Other Big Companies
LLM operators can reduce their carbon footprint by using renewable energy. For example, they could use corporate power purchase agreements (CPPAs) to procure green electricity from wind or solar farms. Google reached 100% renewable energy in 2017 with precisely this approach.34 The company maintained that level by signing additional CPPAs for a cumulative total of 7 gigawatts (GW) through 2021 (equivalent to 44% of the total capacity installed in 2020 in the US35) to cover the rapid expansion of computing conducted in the company’s data centers in the recent years.
Other players have 100% renewable electricity targets; Microsoft is aiming for 2025.36 In other words, tech players’ electricity consumption is less carbon-intensive than the national average. This results in overly high estimates of the carbon footprint of GAI in countries with a highly carbon-intensive grid like the US, since such estimates rely on an average carbon usage per kWh rather than what a tech company actually uses.
Big Tech pioneered CPPA market development, and this leadership translates into other benefits supporting broader impact minimization.37 First, this initiative added to the increasing scrutiny about GAI’s energy consumption and put pressure on other players to follow suit.38 As a result, most GAI will likely run on green electricity in the future. Second, this push from tech players had a positive effect on the entire clean energy industry. These companies’ efforts have pushed growth with substantial investments that kick-started the market and bypassed less agile utilities.
In 2020 alone, Google, Amazon, Facebook, Apple, and Microsoft procured 7.2 GW of renewable capacity, which is almost 30% of all CPPAs, or around 3.5% of all global renewable capacity additions.39 This contributed to making CPPAs an accessible tool for companies to source renewable electricity and offered an alternative to subsidies for developers.
One could argue that these new renewable energy projects could have been developed for other consumers (i.e., they could replace current electricity supply from fossil sources instead of supplying new demand). There is some truth to this, but on balance, we believe the contribution of the tech giants to be positive here, and there remains vast potential for other players and industries to follow suit. For example, this objection does not apply to onsite solar photovoltaic projects that would otherwise not happen.
In addition, in some data center hot spots, such as the Nordics, wind or solar farms would likely not get off the ground without this new demand, given the limited local need for additional renewable energy. Finally, the electricity generation need not sit near the data center, or even in the same country, in the case of integrated electricity grids like in Europe.
Nevertheless, energy usage by LLMs is the latest stage in an ever-increasing thirst for energy across the tech industry, especially among hyperscalers. Globally, data centers may represent a relatively small share of electricity demand, but locally they can play an outsized role.
Grid capacity is limited, and the addition of renewables shifts power generation to new areas and results in an increasingly decentralized system. This complexity, combined with the lengthy process to develop new transmission infrastructure, hobbles energy transition. Hyperscalers will compete for the remaining access to electricity to the detriment of others (which some may consider more crucial to the economy and/or security). In a prime example of this conflict, the Norwegian group Nammo recently blamed a new TikTok data center for preventing the expansion of the group’s ammunition plant supplying Ukraine with artillery rounds. TikTok’s data center had already taken the grid’s spare capacity near the plant.40
The remaining elephant in the room is this: when is the electricity generated? Typically, a company signs a CPPA for a total annual volume of renewable electricity, regardless of when the electricity is generated. So on an annual net basis, it considers its energy consumption green. However, on an hourly basis, there is often a difference between the consumption of the data center and what the wind and solar assets have generated. This disconnect between the timing of the electricity produced and the electricity consumed calls into question whether corporations can honestly call their consumption green.
Thus, the remaining challenge to minimize the environmental impact of GAI’s energy consumption is to make that link in real time, which explains why companies now increasingly focus on procuring electricity in line with their consumption profile or adapt their consumption to the electricity generated. Google aims to establish this link with its “24/7 Carbon-Free Energy by 2030” program.41
Closing Thoughts
Whether or not we have truly entered a phase of global boiling, we can confidently predict an increasing need to reduce carbon emissions. And regardless of how many industries truly reorient around LLMs, we can count on a GAI playing a growing role in our lives. Exactly how these two threads intertwine remains to be seen.
What is certain is that, at present, the emissions from LLMs are relatively insignificant compared to both their popularity and to other everyday activities. At the same time, as compute-intensive LLMs permeate our lives, the extent to which the technology may come to compromise sustainability merits continued attention.
This is particularly true if dreams of democratized AI become a reality; widespread empowerment of diverse grassroots users to host and fine-tune smaller LLMs could complicate efforts to track the technology’s environmental impacts and would create more players with the duty to use it responsibly.
Fortunately, opportunities abound for all participants in the LLM space to strive for responsible AI, from optimizing model-training efficiency to sourcing cleaner energy and beyond. We believe LLM-driven advances in R&D have the potential to turbocharge society’s journey toward net zero. Indeed, a reorienting of green tech around LLM advances may be just the impetus we need.
References
1 Niranjan, Ajit. “’Era of Global Boiling Has Arrived,’ Says UN Chief as July Set to be Hottest Month on Record.” The Guardian, 27 July 2023.
2 Gates, Bill. “The Age of AI Has Begun.” GatesNotes, 21 March 2023.
3 Knight, Will. “OpenAI’s CEO Says the Age of Giant AI Models Is Already Over.” Wired, 17 April 2023.
4 Ludvigsen, Kasper Groes Albin. “The Carbon Footprint of GPT-4.” Medium/Towards Data Science, 18 July 2023.
5 Touvron, Hugo, et al. “Llama 2: Open Foundation and Fine-Tuned Chat Models.” Cornell University, 19 July 2023.
6 Luccioni, Alexandra Sasha, Sylvain Viguier, and Anne-Laure Ligozat. “Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model.” Cornell University, 3 November 2022.
7 Ludvigsen, Kasper Groes Albin. “ChatGPT’s Electricity Consumption.” Medium/Towards Data Science, 1 March 2023.
8 Luccioni et al. (see 6).
9 Barr, Jeff. “Amazon EC2 Update — Inf1 Instances with AWS Inferentia Chips for High Performance Cost-Effective Inferencing.” AWS News Blog, 3 December 2019.
10 Leopold, George. “AWS to Offer Nvidia’s T4 GPUs for AI Inferencing.” HPCwire, 19 March 2019.
11 Tewari, Niharika. “ChatGPT: 10 Most Hilarious and Weird Responses That ChatGPT Has Produced!” Sociobits.org, 14 December 2022.
12 Stokel-Walker, Chris. “Thousands of Planes Are Flying Empty and No One Can Stop Them.” Wired, 2 February 2022.
13 Pennington, Clarke. “Generative AI: The New Frontier for VC Investment.” Forbes, 17 January 2023.
14 Peleg, Yam. “GPT-4’s Details Are Leaked. It Is Over. Everything Is Here.” Archive.today, accessed August 2023.
15 Li, Pengfei, et al. “Making AI Less ‘Thirsty’: Uncovering and Addressing the Secret Water Footprint of AI Models.” Cornell University, 6 April 2023.
16 Kommenda, Niko. “How Your Flight Emits as Much CO2 as Many People Do in a Year.” The Guardian, 19 July 2019.
17 Lavi, Hessam. “Measuring Greenhouse Gas Emission in Data Centres: The Environmental Impact of Cloud Computing.” Climatiq, 21 April 2022.
18 Stoll, Christian, Lena Klaassen, and Ulrich Gallersdorfer. “The Carbon Footprint of Bitcoin.” Massachusetts Institute of Technology (MIT) Center for Energy and Environmental Policy Research (CEEPR), December 2018.
19 Ritchie, Hannah, and Max Roser. “Greenhouse Gas Emissions.” Our World in Data, 2020.
20 Ludvigsen, Kasper Groes Albin. “How to Estimate and Reduce the Carbon Footprint of Machine Learning Models.” Medium/Towards Data Science, 1 December 2022.
21 ”CodeCarbon.” GitHub, accessed August 2023.
22 Luccioni, Sasha. “The Mounting Human and Environmental Costs of Generative AI.” Ars Technica, 12 April 2023.
23 Dettmers, Tim, et al. “QLoRA: Efficient Finetuning of Quantized LLMs.” Cornell University, 23 May 2023.
24 Datta, Souvik. “Introducing No-Code LLM FineTuning with Monster API.” Monster API, 4 July 2023.
25 Dempsey, Paul. “Access for All: The Democratisation of AI.” The Institution of Engineering and Technology, 10 November 2021.
26 Knight (see 3).
27 Masanet, Eric, et al. “Recalibrating Global Data Center Energy-Use Estimates.” Science, Vol. 367, No. 6481, February 2020.
28 Scott, Art, and Ted G. Lewis. “Sustainable Computing.” Ubiquity, Vol. 2021, February 2021.
29 Platt, Moritz, et al. “The Energy Footprint of Blockchain Consensus Mechanisms Beyond Proof-of-Work.” Proceedings of the 21st International Conference on Software Quality, Reliability, and Security Companion (QRS-C). IEEE, 2022.
30 “Driving to 54.5 MPG: The History of Fuel Economy.” Pew, 20 April 2011.
31 Bornstein, Matt, Guido Appenzeller, and Martin Casado. “Who Owns the Generative AI Platform?” Andreessen Horowitz, accessed August 2023.
32 Patel, Dylan, and Afzal Ahmad. “Google ‘We Have No Moat, and Neither Does OpenAI.’” SemiAnalysis, 4 May 2023.
33 Bornstein et al. (see 31).
34 “Operating on 24/7 Carbon-Free Energy by 2030.” Google Sustainability, accessed August 2023.
35 “US Renewable Energy Factsheet.” University of Michigan Center for Sustainable Systems, accessed August 2023.
36 Hook, Leslie, and Dave Lee. “How Tech Went Big on Green Energy.” Financial Times, 10 February 2021.
37 Varro, Laszlo, and George Kamiya. “5 Ways Big Tech Could Have Big Impacts on Clean Energy Transitions.” IEA, 25 March 2021.
38 Hook et al. (see 36).
39 Varro et al. (see 37).
40 Dodgson, Lindsay. “Weapons Firm Says It Can’t Meet Soaring Demand for Artillery Shells Because a TikTok Data Center Is Eating All the Electricity.” Insider, 27 March 2023.
41 Google Sustainability (see 34).



