

CUTTER BUSINESS TECHNOLOGY JOURNAL VOL. 30, NO. 10/11
Giti Javidi, Ehsan Sheybani, and Lila Rajabion present a convincing argument for redistributing the cloud. They suggest that the cost and time associated with transmitting data to the cloud, processing it there, and returning the results back to the IoT devices are critical. Fog computing, as the authors explain, both enhances and complements the cloud by bringing the processing closer to a cluster of IoT devices, resulting in faster analytics.
Big data is not going anywhere soon. In the next few years, businesses of all sizes will be using some form of data analytics to make business decisions. Moreover, as the Internet of Things (IoT) becomes more widespread, high-speed data processing, analytics, and reduced response times will be deemed more critical than ever. Meeting these requirements through the current centralized, cloud-based model faces a multitude of challenges. This is where fog computing can enhance and complement the cloud.
In this article, we discuss fog computing, its advantages, and its current applications. We also highlight how transitioning from cloud to fog can help businesses deal with the current and future challenges of the IoT, including ensuring that their technology infrastructure is better equipped to handle big data.
Peering Through the Fog
Cloud computing involves delivering data, applications, photos, videos, and more, over the Internet to data centers. The IoT refers to the connection of devices (other than the usual devices, such as computers and smartphones) to the Internet, including cars, kitchen appliances, and heart monitors. As the IoT surges in the coming years, more devices will be added to the mix.
Cloud computing and the IoT have a complementary relationship. The IoT generates massive amounts of data, and cloud computing provides a pathway for that data to travel to its destination. In recent years, the IoT has been generating an unprecedented amount of data, which has put a tremendous strain on the Internet infrastructure. In response to this data growth, companies are seeking ways to meet the challenge of data management. Hence, fog computing, also known as edge computing, has begun to soar in the last few years.
Fog computing is an intermediate layer that extends the cloud layer. Simply put, fog is a cloud close to the ground. Fog architecture moves part of the computing to the edges, away from centralized data centers and cloud solutions. It is a “highly virtualized platform that provides compute, storage, and networking services between end devices and traditional cloud computing data centers, typically, but not exclusively, located at the edge of network.” Fog allows data to be processed locally on smart devices rather than being sent to the cloud for processing.
An example can be found in a jet engine, which creates 10 TB of data about its performance and condition in 30 minutes. Transmitting all that data to the cloud and transmitting response data back requires high bandwidth and a great amount of time, which can increase latency. In a fog computing environment, much of the processing would take place on a local router, rather than having to first transmit the data to the cloud. Hence, fogging focuses on lifting part of the workload off the regular cloud services by using localized resources to provide a quicker, smoother, and more streamlined experience for end users. Fog computing analyzes the most time-sensitive data at the network edge, close to where it is generated, instead of sending vast amounts of data to the cloud. Also, in addition to acting on data in milliseconds, it sends selected data to the cloud for historical analysis and longer-term storage. Figure 1 provides an illustration of fog computing.
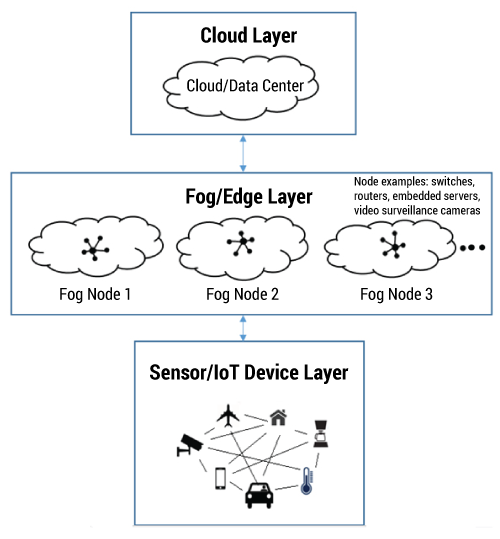
How Is Fog Different From Cloud Computing?
In many cases, fog and cloud complement each other. As a good use case, consider an example of smart vehicles that can collect information about road conditions. These smart vehicles send the collected information not only to drivers within a given radius, but also to a central cloud server when connected to a WAN to inform other drivers on other roads or highways of road conditions (e.g., ice, bumps, traffic). Both fog and cloud provide data, computation, storage, and application services to end users, although fog computing places transactions and resources at the edge of the cloud, rather than establishing channels for cloud storage and utilization.
By accommodating these services and addressing the requirements of IoT systems, the fog layer offers several advantages over the cloud. Fog reduces the need for increased bandwidth by not sending every bit of data over cloud channels, but instead aggregating data at a certain access point. It also reduces latency and eliminates numerous hops, lowers costs, improves efficiency, and supports mobile computing and data streaming.
Fog nodes can be deployed anywhere with a network connection close to the smart device where actual data generation or end outcome takes place (e.g., in a vehicle). One of the immediate benefits of fog over cloud is its proximity to the sensor layer. Moreover, the large-scale geographical distribution of the devices that make up the fog layer, combined with location awareness, ensures low communications latency. The combined benefits of location-awareness and large-scale geographical distribution support the mobility requirements of devices or “things” at the sensor layer. The close proximity of the fog layer to the nodes provides real-time interaction with the sensors and actuators in the sensor layer.
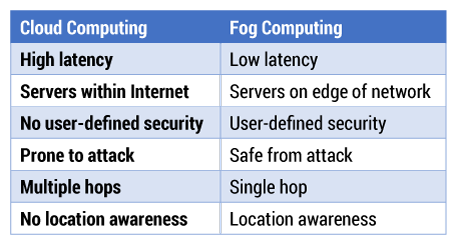
Via fog, companies can also address concerns about scalability and trustworthiness. Fog computing promises to ensure safe and trusted transitions, provide affordable scaling under a shared infrastructure, offer real-time processing and cyber-physical system control, and increase efficiency by pooling unused local resources from participating end-user devices. Some differences between cloud and fog computing are shown in Table 1.
Security is a major reason companies are turning to fog computing, and there are several fundamental ways that fog computing is making the IoT more secure. Fog offers a new level of protection above and beyond IT security. It has the infrastructure to detect attacks by hackers. It also provides real-time incident response services that enable IoT systems to respond to breaches without disruption of service. We believe that it is too early to know for certain whether fog computing is more secure than cloud computing, but certainly it
does address some key vulnerabilities.
For fog computing to operate securely, some issues remain to be resolved. For instance, wireless network security is a big concern, especially with the predominance of wireless in fog networking. Examples of the types of potential attacks include jamming and sniffer attacks. In fog computing, user data is outsourced and the user’s control over data is handed over to the fog node, which introduces the same security threats as those that exist with cloud computing. First, it is difficult to ensure data integrity, since the outsourced data could be lost or incorrectly modified. Second, the uploaded data could be abused by unauthorized parties for other interests. Furthermore, new challenges arise when designing secure storage systems to achieve low latency, support dynamic operation, and deal with the interplay between fog and cloud.
The existing security and privacy measurements for cloud computing cannot be directly applied to fog computing due to fog’s features, including mobility, heterogeneity, and large-scale geographical distribution. Therefore, continued research efforts are needed to determine the impact of those security issues and possible solutions, providing future security-relevant directions to those responsible for designing, developing, and maintaining fog systems.
Cloud and Fog to Mist … and Fluid
To understand fog computing, one must also be familiar with its new permutations: mist computing and fluid computing. Cloud infrastructure is high in the data center, fog infrastructure is between the devices and the cloud, and mist infrastructure is simply the “things/devices.” Mist computing is closer to the ground than fog, which in turn is closer to the ground than the cloud. Mist computing is about bringing compute, storage, and communications directly to the things of the IoT.
Fluid computing is an emerging network architecture that combines cloud, fog, and mist computing into a single abstraction. In other words, each of these three computing layers can be considered as an application of fluid computing in a specific, bounded context. The fluid architecture eliminates the technological separation created by cloud, fog, and mist technologies. As the IoT grows, we anticipate a convergence of cloud, fog, and mist computing platforms toward a fluid computing platform. This convergence will be necessary, if not essential, to accelerate the adoption of the IoT.
Implications for Businesses
Cloud has paved the way for the rapid growth of the IoT, but with such growth, businesses need faster and more efficient solutions than ever, since information that is as new as one day old can lose value. Companies are turning to fog computing for higher efficiency, better security, faster decision-making processes, and lowered operating costs. For many companies, relying on nodes on decentralized systems is a concern. For example, a major disaster could wipe out all those individual processors in a city, resulting in catastrophic data losses. By storing data in the cloud, businesses will be able to recover from disruptions much more quickly and efficiently.
With fog computing, local and remotely hosted data backups remain critical, as does ensuring that businesses can access stored data in the event of an emergency. Fog computing remedies this issue by safely storing data backups and allowing companies to schedule automated backups protected by military-grade encryption. Fog and cloud complement each other in this scenario.
With the emergence of IoT applications, a real-time response can at times be “a matter of life or death.” For example, reliable real-time data processing is crucial for medical wearables, which monitor patient conditions. Fog computing is especially feasible for applications that require a response time of less than a second.
Fog is also extremely useful for less urgent situations. A good example is found in the airline industry. When a plane lands, data from its engines is downloaded and analyzed. If any anomalies are discovered that could indicate trouble with the engine or any potential cause of failure, the problem must be remedied, usually by procuring and installing a new part. The entire process typically takes several hours. With fog computing, airlines have the capability to do all the analytics in-flight, on the plane, and to transmit any anomalies to the destination airport while still in the air. Then, when the plane lands, the needed part can be waiting, reducing downtime to 15 to 30 minutes rather than hours. A look at the transportation and manufacturing industries, with their need for preventive maintenance, shows how embracing fog computing would enhance efficiency and safety across those industries.
As mentioned earlier, security concerns are compelling companies to turn to fog computing. According to the OpenFog Consortium, fog systems are designed “from the ground up for cloud-to-thing IoT security, offering a new level of protection above and beyond IT security.” Fog enables the information exchange between IoT devices and the cloud, which provides security suitable for real-time applications. Fog applications can be used to monitor and analyze data from sensors and, if necessary, trigger an action or an alert. This could be used in many areas, including changing equipment states such as opening or closing a valve in response to flow or pressure readings, or performing security tasks like triggering automated locks or zooming in on a surveillance camera. Fog’s close interaction with sensors can also help predict failures so that a technician can be alerted to carry out a repair before a problem becomes critical.
Conclusion
Fog computing can provide computing, networking, and storage services for the IoT. Consider a system that processes data to learn patterns. The workload can be distributed in such a way that localized patterns are identified in the fog layer, while the generalized patterns are only available in the cloud. This load sharing increases the amount of computing power available to process data. The proximity of the fog layer to the edge makes it an ideal way to react to events in real time and enhances system reliability.
Currently, industries such as healthcare, manufacturing, transportation systems, oil and gas production, and utilities are turning to fog computing. But more and more businesses that deal with a significant amount of data are learning about the potential for fog computing, with the understanding that it cannot entirely replace cloud computing, since cloud is still preferred for the high-end batch-processing jobs that are very common in the business world. Hence, we can conclude that fog computing and cloud computing will complement each other with their advantages and disadvantages.
Fog computing helps the cloud handle the significant amount of data that is generated daily from the IoT. It enables a wide range of benefits, including enhanced security, decreased bandwidth, and reduced latency. These benefits make fog an appropriate paradigm for many IoT services in various applications, such as connected vehicles and smart grids. Nevertheless, fog devices obviously face several security threats, much the same as those faced by traditional data centers, which must be addressed. We, along with many researchers and practitioners, recommend that individual businesses adopt a hybrid model — a combination of cloud, fog, and onsite backup systems — to maintain efficiency while mitigating security risks.